




Meet the only AI assistant built for data. Analyze, document, and answer any data question — fast.
 Learn more
Learn moreFinding and trusting the right data quickly has become a major bottleneck for analytics and AI initiatives. Modern data catalogs address this challenge head-on by surfacing the most relevant, trustworthy data instantly, empowering teams to move faster with confidence. Modern catalog platforms go far beyond basic indexing. They use AI-powered discovery, automated metadata enrichment, and embedded lineage tracking to continuously map and contextualize data across the stack without the need for custom scripts or manual tagging.
Let's a closer look at the leading data catalog tools and features you should look for.
What is a data catalog?
A data catalog is a centralized inventory that provides a searchable and understandable view of all data assets within an organization. It acts like a directory for data, allowing users to discover, understand, and access information more efficiently. By organizing and providing context for data, data catalogs improve data discovery, data governance, and collaboration across teams.
Key features of a data catalog tool
Top data catalog tools comparison
1. Secoda
Secoda is an AI-native enterprise data management platform that combines data cataloging, lineage, governance, quality monitoring, and self-service analytics in one collaborative workspace. iDesigned to reduce manual work and make data truly accessible, Secoda uses AI not only to automate metadata ingestion and documentation but also to power natural language search, generate visualizations, and enable users to conduct self-serve analysis without writing SQL.
By bringing together structured metadata, questions, and team knowledge in one place, Secoda helps both technical and non-technical users quickly find, understand, and trust their data.

Key features
- AI-powered search returns contextual answers to data questions across the stack.
- Self-serve analysis and visualizations powered by Secoda AI - ask questions and get visual insights instantly.
- Automated metadata ingestion, documentation, and quality scoring.
- End-to-end column-level lineage mapping to visualize relationships and dependencies.
- 80+ native integrations with BI tools, data warehouses, orchestrators, and more.
- Centralized governance interface with role-based access control (RBAC), policy enforcement, and granular permissions to manage data access, documentation ownership, and workspace visibility.
- No-code interface with Git-based version control and role-based access permissions.
- Central workspace for documentation, Slack-style Q&A, and data discovery.
Pros
- Strong AI capabilities for search, tagging, documentation, and visualization.
- Enables non-technical users to perform analysis and create charts without SQL.
- Fast deployment with no-code setup and broad out-of-the-box integration coverage.
- Real-time collaboration and intuitive UI drive high adoption across teams.
- SOC 2-compliant for secure data management.
Cons
- Not intended for managing unstructured data.
- Works best when paired with clear internal ownership and metadata practices.
2. Collibra
Collibra offers a Data Intelligence Cloud platform centered around its Data Catalog. It helps users discover and categorize data automatically with a machine learning algorithm. It also includes features like data curation and data lineage tracking, which are also supported by machine learning.

Collibra can also manage metadata with graphs so users can better understand data quality and lineage. It can also automate the process of data discovery and curation across data sources for accurate insights.
Key features
- A centralized repository for business terms to promote a common understanding across the company.
- Artificial intelligence to label and categorize data so it is easier to find.
- Data managers and users can collaborate using built-in chat boards and alerts.
- Collibra helps companies follow data rules like the General Data Protection Regulation (GDPR).
Pros
- Strong integration capabilities
- Robust governance features that enhance data quality
- Active community and support resources for users
Cons
- Time-consuming initial setup and configuration
- Lacks automated lineage and workflows
- Lacks intuitive data visualization and reporting for users
- Lacks AI-assisted search and advanced analytics capabilities
- Less mature data quality functions like observability, security, and connectivity
See a full comparison of Secoda vs Collibra
3. Stemma
Stemma is a fully managed data catalog solution based on the open-source Amundsen platform, which Teradata acquired in 2023. It offers reliable metadata management and enterprise features. Stemma is ideal for companies that want to promote a self-serve data culture. It can also enrich metadata automatically and customize user data experiences.
Stemma can integrate with major data sources like Snowflake, Redshift, and BigQuery. It can improve data discovery and documentation, leading to better team communication.
Key features
- Real-time collaboration for multiple projects.
- Data customization for businesses to meet their specific business needs.
- Stemma can explain the relationships between data assets with a knowledge graph for better understanding.
- It can collect and save data from different sources automatically.
Pros
- Enterprise-grade security
- Personalized user experience
- Better data discovery and accessibility
- Integrates smoothly with existing data infrastructure
Cons
- Limited offline capabilities
- Costs can be high for small companies
- Limited technical documentation and demos
- Lacks advanced data governance and visualization features
- Integration challenges with certain legacy or uncommon data systems
4. SelectStar
SelectStar is an intelligent data discovery platform. It simplifies data governance and management with automatic data cataloging and usage insights. The tool is designed to help teams find and trust their data.

SelectStar can analyze and display column-level data lineage. This process makes sure that users always know where data comes from and how it is being used. Its user-friendly interface allows both technical and non-technical stakeholders to engage with data efficiently.
Key features
- Monitors and alerts users to any changes in data schemas to reduce the risk of errors.
- Allows users to search across all data sources to prioritize results based on popularity and relevance.
- Generates and maintains up-to-date documentation for data assets to reduce manual effort and improve accuracy.
- Provides granular control over data access so only authorized users can view or modify sensitive data.
- Easily connects with popular BI tools to enhance data accessibility for reporting and analysis.
Pros
- Quick and easy setup with minimal configuration.
- Intuitive UI accessible to both technical and non-technical users.
- Highly automated with minimal manual tagging required.
- Flexible integration options through open API.
Cons
- Lacks deep AI-powered workflows and predictive metadata suggestions.
- More limited customization and extensibility compared to developer-centric tools.
- Advanced data quality and observability features are not built-in.
- Git-based version control and semantic search not available.
5. Alation
Alation is another popular legacy data catalog and data intelligence platform. It makes it simple for companies to find and trust their data.

Alation is the foundation for data intelligence, centralizing data context and policies. This helps create a single source of truth and streamline data management. Alation also offers a simple interface with collaborative features that connect data stewards and business users.
Key features
- Users can build wiki pages, searchable chats, and subscribe to data updates.
- Customizable reporting and data insight are available through the Alation Cloud Service.
- Helps with the creation of custom connectors to integrate with various data sources.
- AI-powered SQL editor helps with queries and flags deprecated data to ensure accuracy.
Pros
- User-friendly interface
- Centralized data context
- Flexible and scalable for enterprise
- Prebuilt connectors simplify integration
Cons
- Limited AI/ML functionality
- Costly for smaller organizations
- Insufficient curation progress tracking and analytics
- Customization options may be limited compared to open-source alternatives
- Closed legacy platform, unable to support federated or distributed models like Data Mesh and Data Fabric
6. Castor (acquired by Coalesce.io)
Castor is an automated data catalog tool. Its main purpose is to improve data documentation and organize it for easy access. It uses AI to generate descriptions for data assets so teams can easily access and understand their data.

Castor centralizes documentation from various sources for a unified repository. This promotes collaboration and transparency across the company. Unlike traditional data catalogs, Castor integrates conversational AI to make it easy for users to interact with data intuitively and retrieve insights with natural language queries.
Key features
- Automates the creation and updating of data documentation.
- Sends real-time updates and notifications via Slack.
- Connects key business metrics directly to relevant data assets.
- Organizes data using simple tags and categories.
Pros
- User-friendly interface
- Automated syncing keeps documents update
- Make data understandable
- Better compliance with regulations
Cons
- Vague data quality processes
- Limited functionality for integrations
- Data monitoring and observability not available
- Doesn’t offer data quality tools for quality checks
7. Atlan
Atlan is a traditional data catalog. Atlan enables easy and intuitive self-service analytics through its data discovery tools. Atlan also offers tools for data lineage, data governance and more.

Key features
- Natural language search to find data using keywords and related synonyms.
- Business context search to discover assets linked to specific business metrics.
- Custom filters based on metadata properties for a tailored search.
- Companion search to validate data choices.
Pros
- Decent and intuitive user interface
- Good customer support team
- Vast tech stack connectivity
Cons
- Expensive contracts starting at over $100K
- Initial learning curve
- Expensive for what you get
- Lacks integrated data quality modules
- AI-driven insights require additional costs
8. Amundsen
Amundsen is an open-source platform developed by Lyft that simplifies data discovery and management for teams. It is used by analysts, data scientists, and data engineers who need quick access to reliable data.

For analysts and data scientists, Amundsen offers an easy-to-use search feature to find and understand data. It contributes to the breakdown of barriers between various data sources. Amundsen automatically refreshes data context for data engineers and software engineers, reducing disruptions and ensuring the correct data is used.
Key features
- Detailed metadata like user stats and last updated information.
- Simple search to find data quickly and recommendations based on names, descriptions, and activity.
- See frequently used data, ownership, and common queries, helping to understand and leverage shared knowledge.
- Context sharing to update table and column descriptions, minimizing confusion and unnecessary back-and-forth communication.
Pros
- Easy to use and integrate
- Straightforward metadata ingestion
- Quick setup for Docker, EC2, and Kubernetes
Cons
- Less active community
- No granular access control
- Versioning system unavailable
- Doesn’t offer built-in data quality and data governance features
- Lesser advanced features compared to other commercial tools
9. Apache Atlas
Apache Atlas is an extensible governance platform designed for Hadoop ecosystems. It provides metadata management and data governance capabilities. Through integrations with various enterprise systems, it enables organizations to build and maintain a data catalog, classify assets, and ensure compliance, making it easier for teams to collaborate on data governance.

Apache Atlas is an extensible governance platform designed for Hadoop ecosystems. It provides metadata management and data governance capabilities. Through integrations with various enterprise systems, it enables organizations to build and maintain a data catalog, classify assets, and ensure compliance, making it easier for teams to collaborate on data governance.
Key features
- Support for predefined and custom metadata types
- Dynamic classifications for data, including PII and data quality
- REST APIs for seamless integration and management
- Intuitive UI for data lineage tracking across processes
- Fine-grained metadata access control through Apache Ranger
Pros
- User-friendly UI
- Scalable for large enterprise environments
- Customizable metadata management
- Integration with Apache Ranger for security and data masking
Cons
- Slow response time
- Lacks data governance tools
- Laborious and resource-intensive initial setup and learning processes
- Significant configuration required to meet specific enterprise requirements.
10. Data.world (Acquired by ServiceNow)
Data.world is a comprehensive data catalog platform that accelerates data discovery and fosters collaboration using AI-driven tools like Archie Bots. The platform enables users to quickly search, explore, and manage data.

Key features
- AI-assisted search with deep contextual results
- Natural-language interaction for data queries
- Auto-enrichment of data and metadata with Archie Bots
- Knowledge-graph powered search for deeper exploration
Pros
- Interactive and easy-to-use UI
- Easy download and integration
- Enhances decision-making through AI-driven insights
- Empowers non-technical users with self-service data discovery
Cons
- Limited documentation and delayed customer support
- Graphs and charts could be more advanced and visually intuitive
- Steep learning curve for new users, requiring additional training
- Lacks diversity and may not stay updated with the latest technologies
- Insufficient data availability for specific use cases like hyperspectral images
11. Informatica Cloud Data Governance and Catalog
Informatica’s Cloud Data Governance and Catalog is a unified solution that combines metadata management, data governance, and discovery into a single platform. Built on the Intelligent Data Management Cloud (IDMC), it leverages Informatica’s AI engine, CLAIRE, to automate metadata ingestion, classification, and linking of business terms to technical assets. The platform supports a wide range of cloud and on-prem data sources, BI tools, ETL processes, and business applications.
With features like lineage visualization, collaborative annotations, and quality scorecards, the catalog supports both enterprise governance teams and business users looking to navigate complex data environments with confidence.
Key features
- CLAIRE AI engine automates metadata discovery, classification, and linkage.
- Natural language search and hierarchical views for browsing metadata.
- Built-in lineage and impact analysis tools for data flow visibility.
- Data quality metrics, profiling insights, and rule-based scorecards.
- Knowledge graph to visualize data relationships and dependencies.
- User collaboration features including Q&A, reviews, and asset ratings.
Pros
- Deep enterprise-grade features for governance, lineage, and quality.
- Strong AI and machine learning integration through CLAIRE.
- Supports both business and technical users with self-service access.
- Extensive ecosystem integration with Informatica and third-party tools.
Cons
- Licensing and platform costs may be prohibitive for smaller teams.
- Initial learning curve due to breadth of functionality.
- Requires commitment to Informatica’s broader cloud ecosystem.
- Customization options may require professional services.
12. Marquez
Marquez is an open-source metadata service originally built at WeWork to streamline metadata management and lineage tracking. It focuses on helping teams discover, visualize, and understand data assets as they move through pipelines. Marquez is tightly coupled with OpenLineage, providing real-time visibility into data transformations, especially when paired with tools like dbt and Apache Airflow. Now part of the Linux Foundation’s AI & Data project, Marquez continues to evolve as a flexible solution for managing metadata and lineage at scale.
Key features
- Tracks data jobs and datasets to provide end-to-end lineage context.
- Integrates seamlessly with modern orchestration tools like dbt and Airflow.
- OpenLineage support for real-time, standardized lineage collection.
- Visualizes relationships between datasets, jobs, and transformations.
- RESTful API and web UI for exploring metadata and lineage.
Pros
- Strong open-source community support and regular updates via Slack and GitHub.
- Lightweight and easy to deploy for engineering-focused teams.
- Enables self-service lineage exploration and root cause analysis.
- Ideal for modern data stacks using orchestration tools like Airflow and dbt.
Cons
- No dedicated managed or enterprise offering.
- Lacks integrated data quality, governance, or cataloging UI features.
- Requires engineering resources to deploy, maintain, and customize.
- Limited support for business user accessibility compared to commercial tools.
13. DataHub
DataHub is a modern, event-based metadata platform originally developed at LinkedIn and open-sourced in 2020. Since then, it has grown into a robust community-led project now primarily maintained by Acryl, which also offers a managed SaaS version. Designed to be extensible and developer-friendly, DataHub provides granular metadata tracking, real-time lineage, and schema evolution monitoring across complex data ecosystems. Its event-driven architecture allows metadata changes to be processed asynchronously, ensuring a scalable and responsive experience.
Key features
- Event-driven architecture captures and tracks metadata changes in real time.
- Supports integration with Kafka, MySQL, Elasticsearch, and Helm for deployment.
- Metadata Change Events (MCEs) and Metadata Audit Events (MAEs) enable extensibility and modular control.
- Rich Python SDK for custom metadata ingestion and automation.
- Native support for search, lineage, and schema versioning.
Pros
- Strong open-source community with active development and documentation.
- Highly extensible and customizable through APIs and SDKs.
- Enterprise-friendly with optional managed SaaS from Acryl.
- Real-time metadata change tracking enables dynamic lineage and observability.
Cons
- Requires engineering effort to configure, deploy, and maintain.
- Complex infrastructure dependencies (Kafka, Elasticsearch, MySQL).
- UI and usability geared more toward technical users.
- No built-in data quality or business glossary tools compared to broader platforms.
14. IBM Knowledge Catalog
IBM Knowledge Catalog is a comprehensive metadata management tool designed to support AI, machine learning, and analytics use cases. It integrates with IBM’s InfoSphere Information Governance Catalog to unify metadata from both on-premises and cloud environments. With support for structured, unstructured, and semi-structured data, the platform enables intelligent data discovery and governance.
Key features
- Intelligent cataloging of diverse asset types including ML models and unstructured data.
- Role-based access control and dynamic data masking for secure governance.
- Automated policy management and privacy rule enforcement.
- Visual relationship diagrams to understand complex data dependencies.
- Integration with IBM Cloud Pak for Data and support for hybrid deployments.
Pros
- Enterprise-grade governance with deep support for regulatory compliance.
- Built-in data privacy and quality controls.
- Flexible deployment options for hybrid or multi-cloud environments.
- Scales well for large enterprise data ecosystems.
Cons
- Steep learning curve and heavy implementation requirements.
- Interface and usability are more suited to enterprise IT teams than self-serve data users.
- Limited openness compared to modern open-source catalog platforms.
- Cost may be prohibitive for smaller organizations or lean teams.
15. Dataproc Metastore (Google Cloud Data Catalog)
Dataproc Metastore, also known as Google Cloud Data Catalog, is a fully managed metadata management and data discovery tool built into the Google Cloud ecosystem. Delivered as a serverless service, it enables organizations to manage and annotate metadata across both cloud and on-premises environments without managing infrastructure. It integrates tightly with services like BigQuery, Cloud Storage, Dataproc, and Pub/Sub, and is accessible through Google’s Dataplex data fabric.
The tool supports natural language queries and tagging at scale, making it useful for both technical and business users aiming to organize, discover, and govern data efficiently.
Key features
- Serverless architecture eliminates the need for infrastructure management.
- Automatically syncs technical metadata from integrated services.
- Natural language search and tagging for easier metadata annotation.
- Unified view of cloud and on-premises data assets.
- Built-in integration with IAM and Data Loss Prevention (DLP) for governance and security.
- Supports custom tag templates and metadata schemas from Cloud Storage.
Pros
- Seamless integration with the Google Cloud ecosystem.
- Scalable and cost-efficient through serverless delivery.
- Strong support for sensitive data identification and labeling.
- Designed for both business and technical users.
Cons
- Primarily benefits organizations already invested in Google Cloud.
- Limited customization and flexibility outside the GCP environment.
- Fewer advanced AI-powered features compared to newer catalog tools.
- Dependency on Dataplex UI may require additional training for unfamiliar users.
16. OpenMetadata
OpenMetadata is an open-source data catalog developed by the architects of Uber’s data platform. It takes a distinct approach to metadata management by avoiding traditional dependencies like graph databases and full-text search engines. Instead, it leverages PostgreSQL’s native capabilities for managing relationships and search, resulting in a simpler, more streamlined backend design.
Focused on centralizing metadata for governance, quality, and collaboration, OpenMetadata provides a wide range of connectors to modern data tools and is actively maintained by a growing open-source community.
Key features
- Centralized platform for metadata management, lineage, profiling, and quality.
- Uses PostgreSQL for storing relationships and search instead of graph or search-specific databases.
- Supports metadata ingestion from modern cloud and data platforms.
- Enables collaboration through metadata annotations, tags, and ownership assignments.
- Offers APIs and SDKs for custom integrations and automation.
Pros
- Strong open-source foundation with active community development.
- Simpler infrastructure requirements due to PostgreSQL-only architecture.
- Comprehensive feature set for governance and observability.
- Flexible integration support across cloud data ecosystems.
Cons
- Still maturing compared to more established commercial tools.
- Requires engineering effort for deployment and scaling.
- UI and user experience are more technical and less polished for business users.
- Limited AI assistance and automation compared to newer platforms.
17. Zeenea
Zeenea is a cloud-native data catalog and metadata management platform designed for scalability and flexibility. Its SaaS-based architecture supports integrations with virtually any data source, enabling centralized visibility into both physical and logical metadata. Zeenea’s intuitive interface helps users explore data through smart keyword search, filtering, and direct browsing, while fostering trust through detailed lineage graphs and traceability features.
The platform also includes tools for compliance reporting and a corporate business glossary to standardize terminology across the organization.
Key features
- Supports physical and logical metamodels for comprehensive metadata representation.
- Smart keyword search with intelligent filters and direct catalog browsing.
- Interactive lineage graph for visualizing data flow and dependencies.
- Traceability and compliance tools to assist with audit readiness.
- Centralized business glossary for consistent enterprise terminology.
Pros
- Easy to deploy and scale via SaaS delivery.
- Strong focus on usability and accessibility for business users.
- Enhances data trust through transparent lineage and compliance support.
- Flexible integration with a wide range of data sources.
Cons
- Limited advanced AI and automation features compared to newer platforms.
- May require additional third-party tools for full version control.
- Less community visibility and adoption than larger open-source or enterprise players.
- Metadata enrichment capabilities can be more manual than fully automated platforms.
18. Boomi Data Catalog and Preparation
Boomi Data Catalog and Preparation is part of the broader Boomi AtomSphere Platform, which also includes integration, master data management, and API management capabilities. This tool offers a centralized data catalog with built-in data preparation features to cleanse, enrich, and standardize data across environments. It supports end-to-end data lifecycle management through extensive connectivity, automation, and collaboration features.
With support for over 1,000 endpoints and 200+ applications, the catalog enables seamless data integration across systems while offering intuitive data governance and discovery tools for business and IT teams alike.
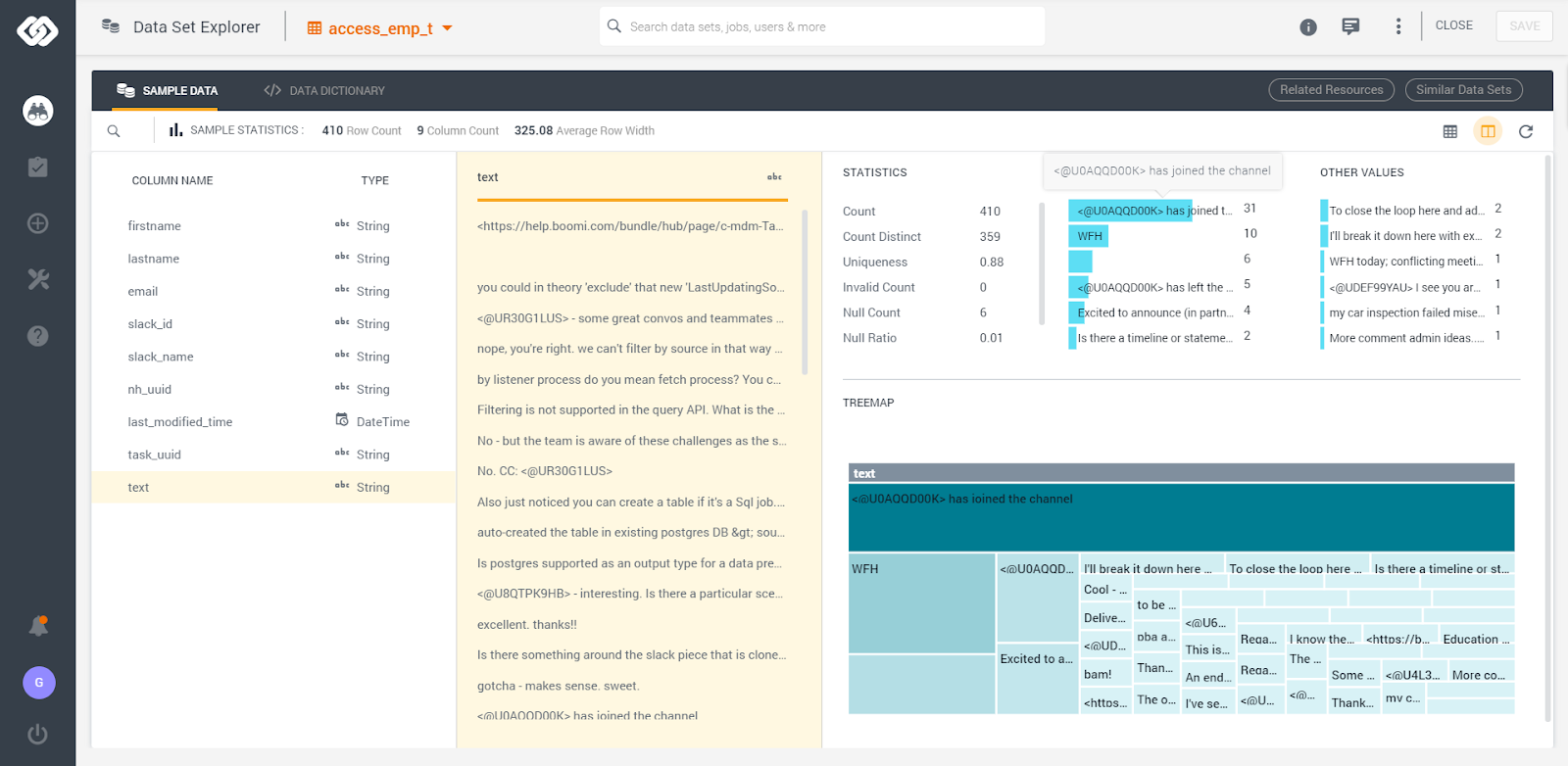
Key features
- Automated data prep engine for cleansing, enrichment, normalization, and transformation.
- Natural language search and personalized data queries.
- Supports deployment in cloud, on-premises, or hybrid environments.
- Integration with 1,000+ endpoints and 200+ apps for streamlined data access.
- Built-in collaboration tools including dataset ratings, comments, and steward access requests.
Pros
- Strong integration ecosystem with extensive prebuilt connectors.
- Versatile deployment options across hybrid and multi-cloud setups.
- Combines data cataloging and preparation in one platform.
- Intuitive for business users with natural language interface and feedback tools.
Cons
- Less focus on advanced lineage and AI-driven cataloging compared to modern platforms.
- May require additional licensing for full platform functionality.
- User interface can feel enterprise-heavy for smaller teams or agile use cases.
- Lacks the open-source flexibility of developer-first tools.
19. Gravitino
Gravitino is a next-generation open-source metadata lake built for scale, performance, and global distribution. Designed to unify metadata across diverse data and AI assets, it operates server-side using Apache Iceberg and exposes consistent access through REST APIs. Gravitino acts as a federated hub for metadata, providing interoperability across data ecosystems while offering strong support for Iceberg's REST catalog interface.
Its modular architecture supports a wide range of use cases through pluggable components, including authentication, authorization, metrics, and event-driven extensions.
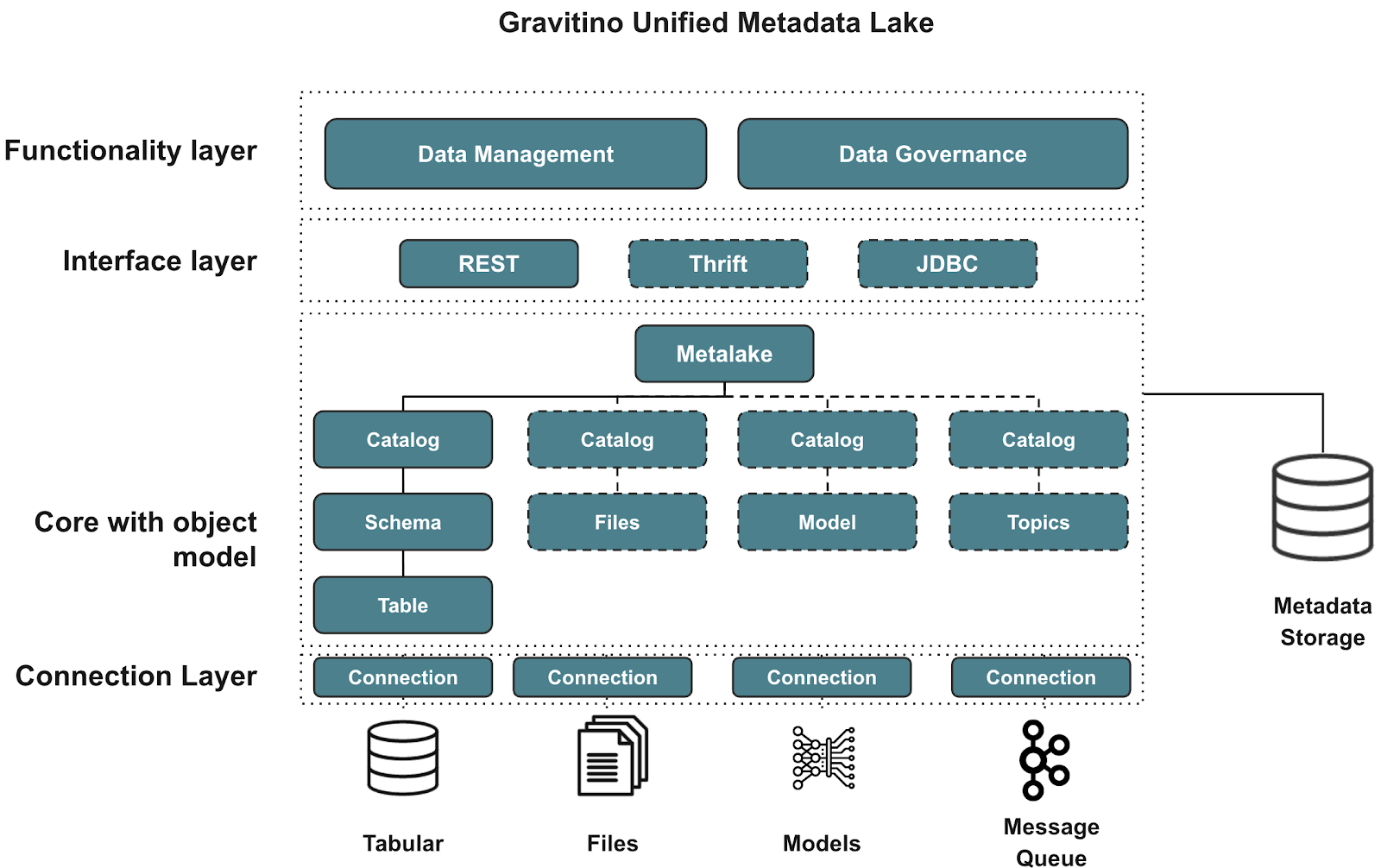
Key features
- Federated and geographically distributed metadata management.
- Native support for Apache Iceberg and the Iceberg REST catalog API.
- RESTful metadata access across multiple data types and locations.
- Full namespace and table management functionality (create, delete, modify, rename).
- Modular architecture with pluggable interfaces for auth, metrics, and event listeners.
Pros
- High-performance architecture designed for modern, distributed data ecosystems.
- Strong interoperability with existing Iceberg-based environments.
- Open-source and community-driven with a modular, extensible design.
- Ideal for unifying metadata across diverse and large-scale systems.
Cons
- Emerging platform with fewer out-of-the-box integrations than established catalogs.
- Requires Iceberg familiarity and deeper technical expertise to implement.
- Lacks native UI and business-friendly features for non-technical users.
- Limited built-in governance, lineage, or AI search functionality compared to all-in-one platforms.
20. Ataccama Data Catalog
Ataccama Data Catalog is part of the Ataccama ONE platform, a unified solution for automating data governance, quality, and management using AI. It supports a wide range of data sources, from on-prem systems to cloud environments, and provides a rich set of features for discovering, profiling, and managing metadata. Built to serve both technical and business roles, the catalog integrates seamlessly with data quality and policy enforcement workflows.
Designed for enterprises with complex data environments, Ataccama delivers both automation and fine-grained control over how data is discovered, validated, and used.
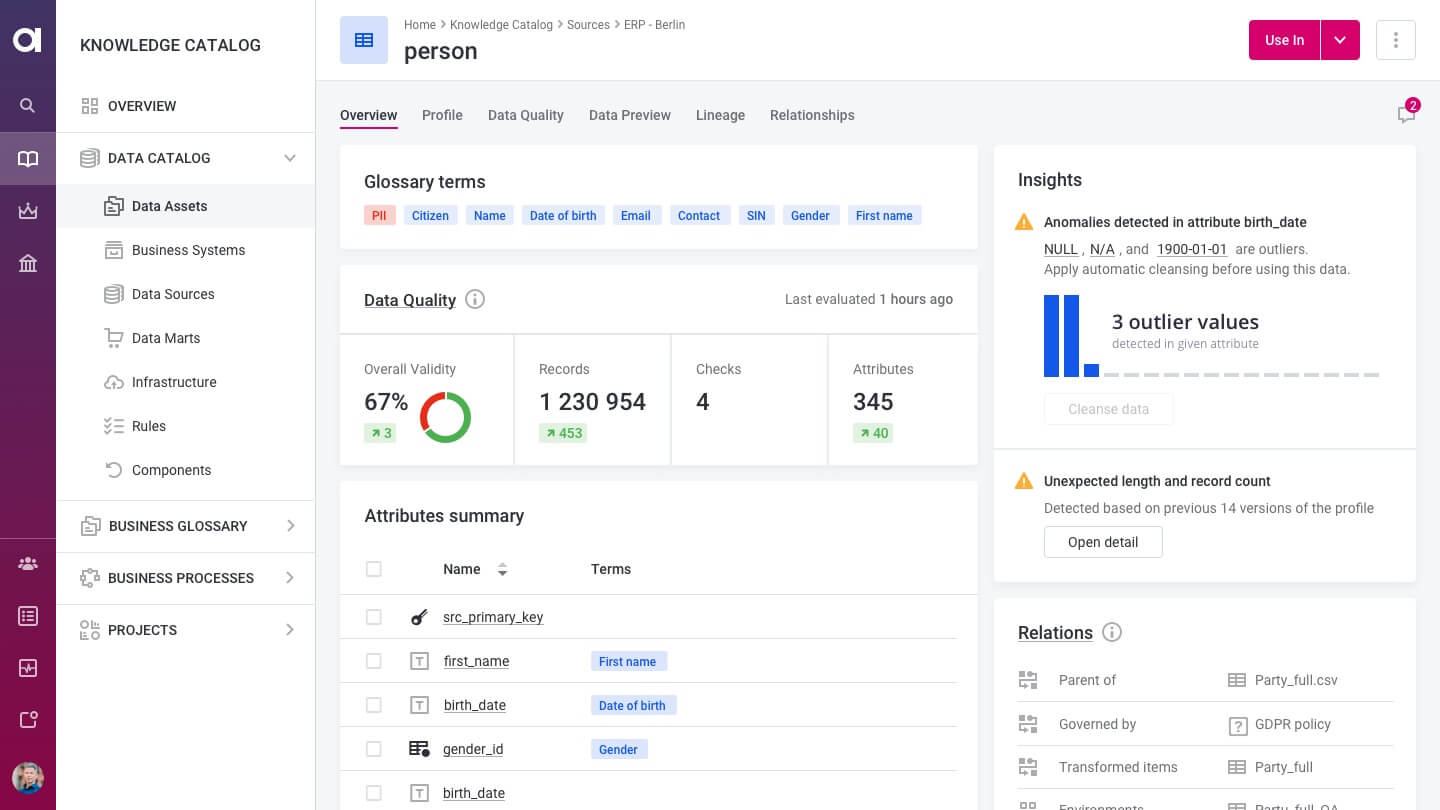
Key features
- Automated discovery and change detection across databases, data lakes, and file systems.
- Continuous data quality monitoring and anomaly detection.
- End-to-end lineage, profiling, classification, and relationship discovery.
- Customizable workflows for data stewards, engineers, analysts, and business users.
- Built-in metadata management with policy enforcement and permission controls.
Pros
- Deep feature set for enterprise data governance and observability.
- Highly configurable to suit various organizational roles and processes.
- Strong automation for quality evaluation and issue detection.
- Tight integration with the full Ataccama ONE platform.
Cons
- Requires significant investment in setup and configuration.
- More suited for large enterprises than smaller or mid-sized teams.
- Complex interface may require training for new users.
- Limited open-source community compared to other platforms.
21. AWS Glue Data Catalog
AWS Glue Data Catalog is a central metadata repository built for use with AWS Glue, Amazon’s fully managed ETL service. It provides persistent storage for table definitions, schema versions, and metadata, enabling data teams to annotate, discover, and share information across AWS data services. Compatible with Apache Hive, it can also act as an external metastore for Hive data environments.
The catalog supports integration with AWS Lake Formation, Athena, Redshift Spectrum, EMR, and Amazon DataZone, making it a key component of data governance and analytics workflows in the AWS ecosystem.
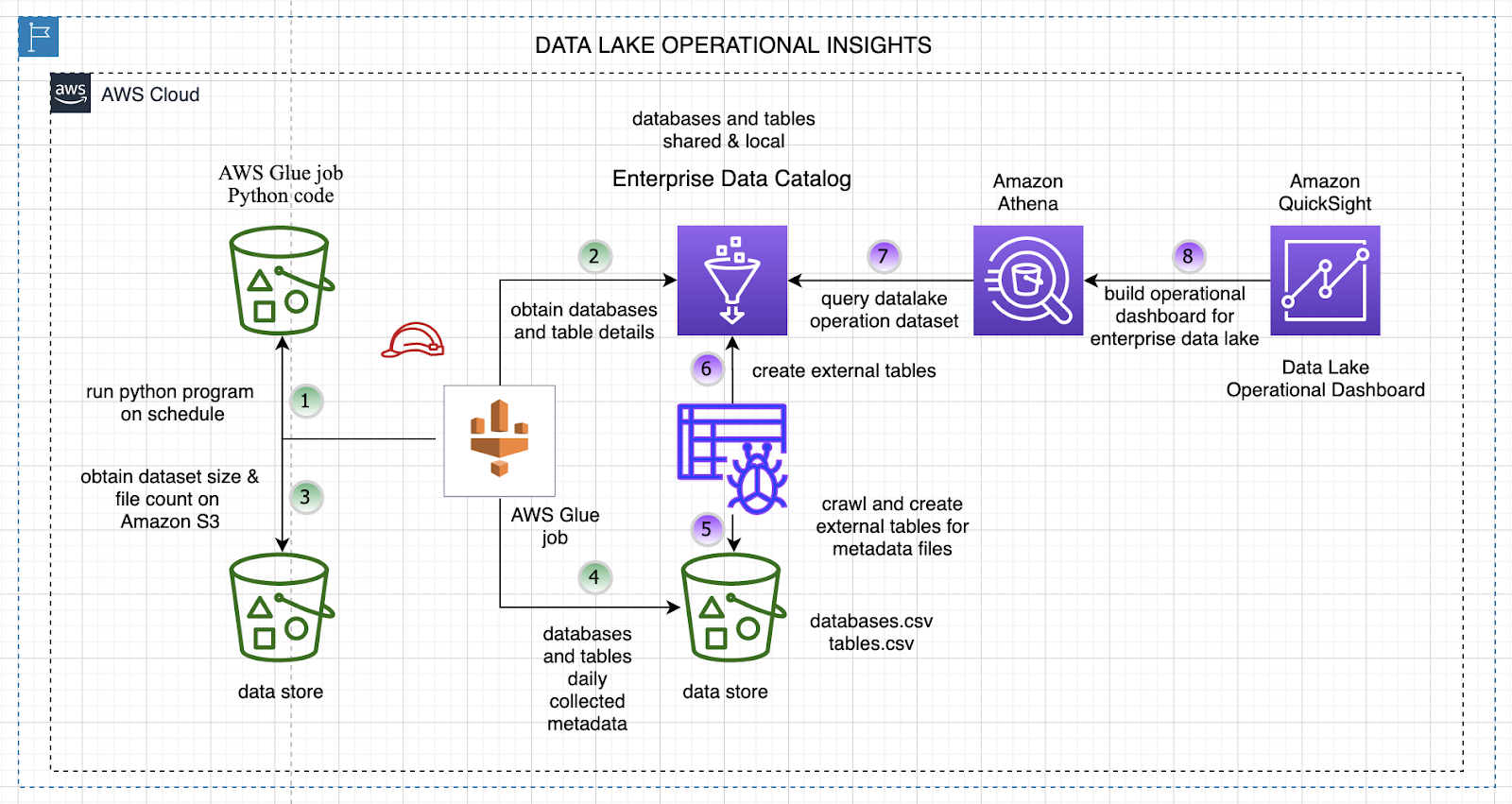
Key features
- Persistent metadata storage for use in ETL and analytics pipelines.
- Crawlers for automatic schema and metadata extraction from repositories.
- Records schema changes and access control settings to enforce governance.
- Provides lineage information including transformation history.
- Integrates with Amazon DataZone to build business-facing data catalogs.
- Native compatibility with AWS Lake Formation for fine-grained access control.
Pros
- Deep integration with AWS services and native support for Hive metastore.
- Scales easily with AWS infrastructure and workflows.
- Automates schema detection with built-in crawlers.
- Central to building secure, governed data lakes in AWS.
Cons
- Best suited for AWS-centric environments, limited utility outside of AWS.
- UI and metadata search capabilities are less intuitive than modern standalone catalogs.
- Lacks cross-platform flexibility compared to vendor-neutral tools.
- Business user features like glossary management and collaboration are minimal.
22. BigID Data Catalog
BigID Data Catalog is part of the broader BigID Data Intelligence Platform, which focuses on data privacy, security, and governance. Powered by AI and machine learning, the catalog automates discovery, profiling, tagging, and classification of both structured and unstructured data across cloud and on-premises environments. It enables organizations to locate, contextualize, and govern their data at scale.
The catalog also helps identify ungoverned or insecure assets, deduplicate entries, and ensure data is aligned with preservation policies and governance standards. Users can explore metadata and policies using natural language queries for a more intuitive experience.
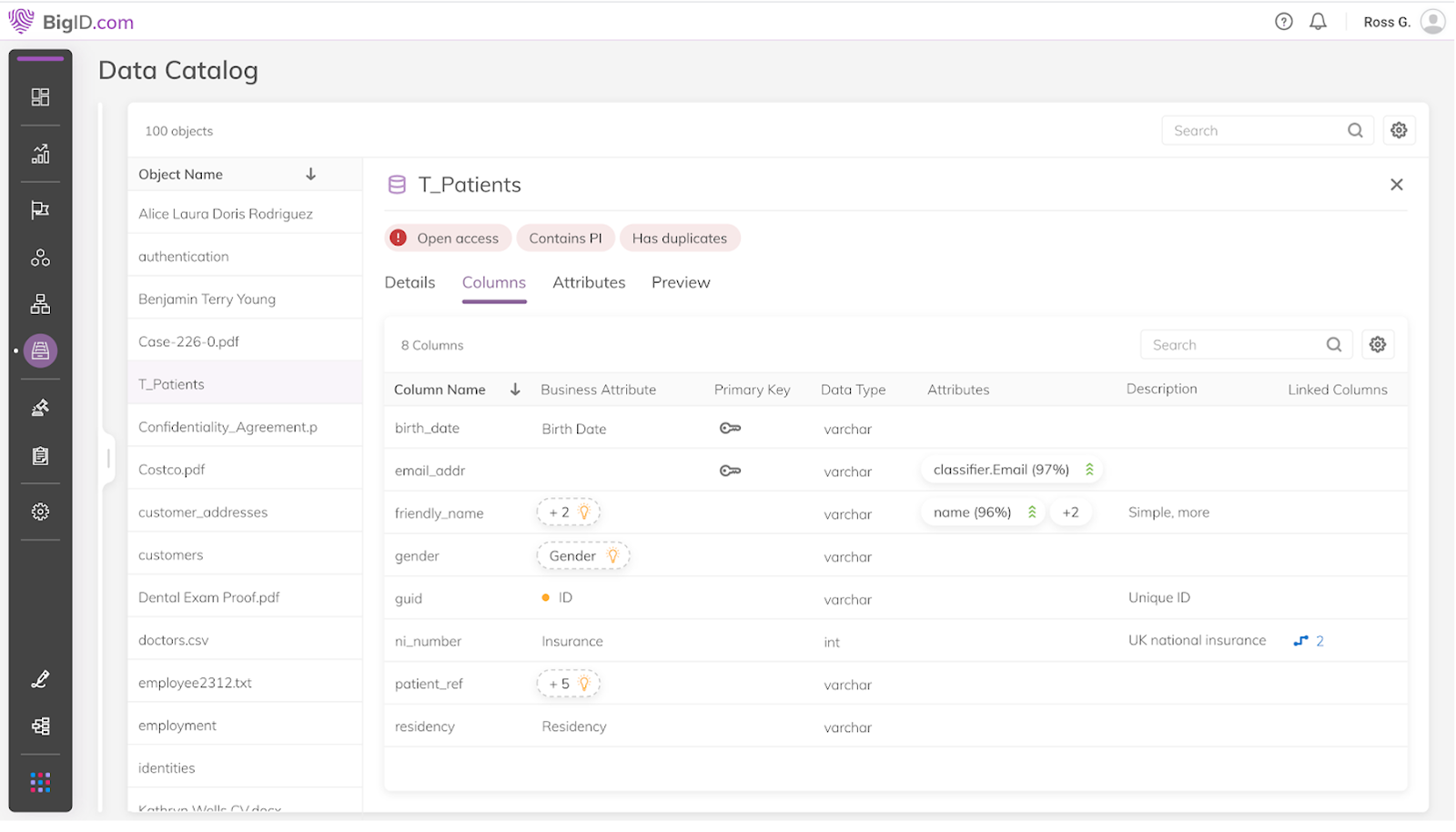
Key features
- AI-driven discovery, profiling, and metadata tagging across hybrid environments.
- Natural language search for metadata and governance-related insights.
- Detects duplicate, ungoverned, or insecure data assets.
- Native integration with 150+ cloud and on-prem data sources.
- Deep learning and NLP-based categorization techniques.
- Quick-access feature to revisit recently viewed data assets.
Pros
- Strong focus on data privacy and security compliance.
- Automates data cataloging across highly diverse environments.
- Advanced ML capabilities for deep data classification and tagging.
- Integrated with broader BigID platform for unified governance workflows.
Cons
- Tailored more for compliance and risk teams than casual data consumers.
- Interface can be complex for business users without technical background.
- Requires upfront configuration and tuning for best results.
- May be overkill for organizations without heavy governance or security needs.
23. Erwin Data Catalog by Quest
Erwin Data Catalog by Quest is an enterprise-grade solution that automates the discovery, cataloging, and curation of metadata. As part of the broader Erwin Data Intelligence Suite, it supports data mapping, lifecycle management, lineage tracking, and sensitive data classification. The tool integrates with a wide range of data sources, from traditional databases to streaming platforms and BI tools, and works alongside Erwin’s data literacy and quality products for end-to-end governance.
Erwin helps accelerate transformation and documentation through automation, making it a good fit for organizations with complex data environments.
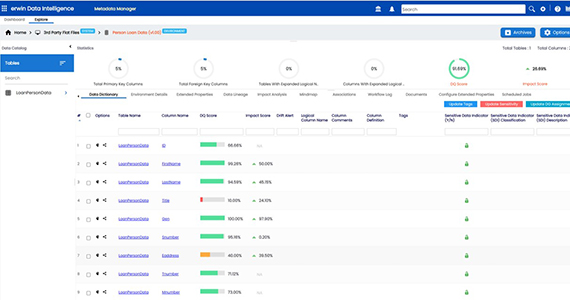
Key features
- Automated metadata discovery, cataloging, and documentation.
- Impact analysis tools to assess downstream effects of metadata changes.
- Sensitive data tagging and classification for compliance support.
- Data mapping, reference data, and lifecycle management built in.
- Central dashboard to evaluate catalog structure, quality, and use.
- Supports transformation automation and code generation.
Pros
- Deep functionality for enterprise metadata and governance operations.
- Streamlines data preparation and documentation with automation.
- Strong integration with the Erwin Data Intelligence Suite.
- Robust impact analysis and lineage tracking features.
Cons
- UI can feel dated compared to newer catalog platforms.
- Primarily designed for technical and governance professionals.
- Initial configuration and setup can be time-intensive.
- Less accessible for business users seeking self-service capabilities.
24. OvalEdge
OvalEdge is a data catalog platform designed to power enterprise data governance while remaining accessible and cost-effective. Positioned as a self-service catalog with marketplace-style navigation, OvalEdge allows users to search and explore data using natural language or BI tools. It connects to over 100 data sources and applies AI and machine learning to automatically classify, tag, and prioritize datasets based on usage and context.
The platform is built to serve multiple user personas with tailored tools, while maintaining governance through granular, role-based access controls and built-in collaboration features.
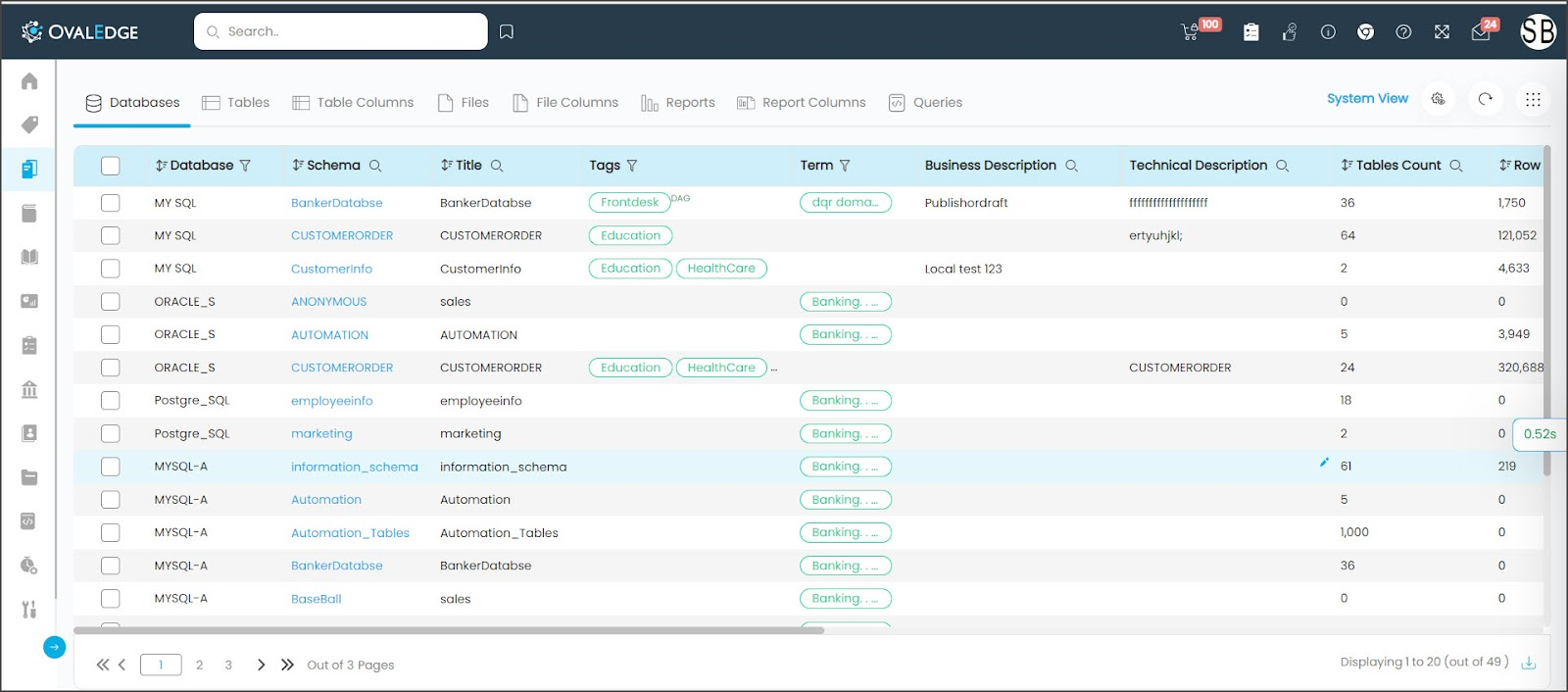
Key features
- Connects to 100+ data sources and indexes metadata automatically.
- AI-powered classification using tags, usage data, and algorithms.
- Role-based access control at both data asset and column levels.
- Data profiling provides statistical summaries of datasets.
- Self-service tools tailored to different user roles and teams.
- Collaboration via built-in chat and Slack integration.
- Data quality alerts and update notifications for catalog users.
Pros
- Affordable and user-friendly solution for growing teams.
- Good balance of governance controls and self-service features.
- Tailored UI and workflows for business users and data teams.
- Built-in collaboration encourages team engagement with data assets.
Cons
- Smaller user community compared to leading open-source or enterprise tools.
- Fewer advanced observability or lineage features out of the box.
- AI and automation may require tuning for accuracy and relevance.
- May require additional configuration for complex governance frameworks.
25. Talend Data Catalog (by Qlik)
Talend Data Catalog, now part of Qlik’s data quality and governance portfolio, is a robust metadata management solution designed to simplify data discovery and compliance. It automatically crawls and profiles data from a wide range of sources, enriching metadata and building semantic context through advanced mapping features. The catalog emphasizes privacy, governance, and collaboration, aligning well with enterprise data stewardship initiatives.
With support for data lineage, role-based controls, and integrated glossary editing, Talend helps organizations build trust in their data while maintaining regulatory compliance.
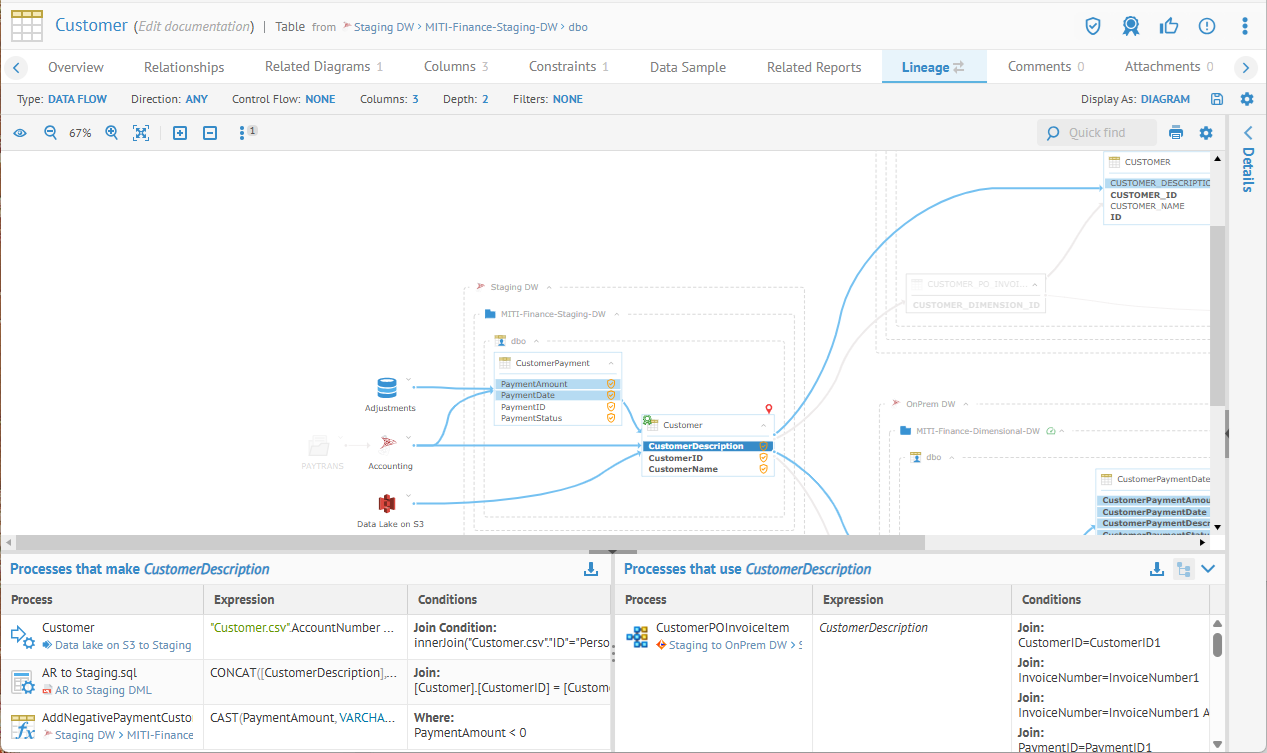
Key features
- Automated metadata crawling, profiling, and enrichment.
- Semantic mapping to link similar data elements with contextual understanding.
- Data sampling and profiling tools to assess completeness and quality.
- Lineage tracking for transparency and impact analysis.
- Role-based permissions for managing data asset responsibilities.
- Collaboration features for editing business glossary and metadata.
Pros
- Strong profiling and enrichment capabilities.
- Seamless integration with other Talend and Qlik governance tools.
- Built-in compliance and privacy rule enforcement.
- Clear lineage and semantic mapping support for better context.
Cons
- Requires investment in the broader Qlik/Talend ecosystem for full value.
- Less modern UI compared to newer platforms.
- Not as extensible or open as developer-focused catalogs.
- Fewer AI-powered features for search and recommendation.
26. Azure Data Catalog
Azure Data Catalog is a centralized metadata repository developed to help developers, data scientists, and analysts discover, annotate, and utilize datasets across an organization. Designed with a crowdsourced model, the platform encourages collaboration by allowing users to contribute custom metadata, tags, and documentation to registered data sources. It serves as a lightweight data cataloging layer within the Azure ecosystem, supporting community-driven metadata enrichment.
While the platform emphasizes simplicity and collaboration, it has gradually been complemented by Microsoft Purview for more advanced governance and compliance needs.
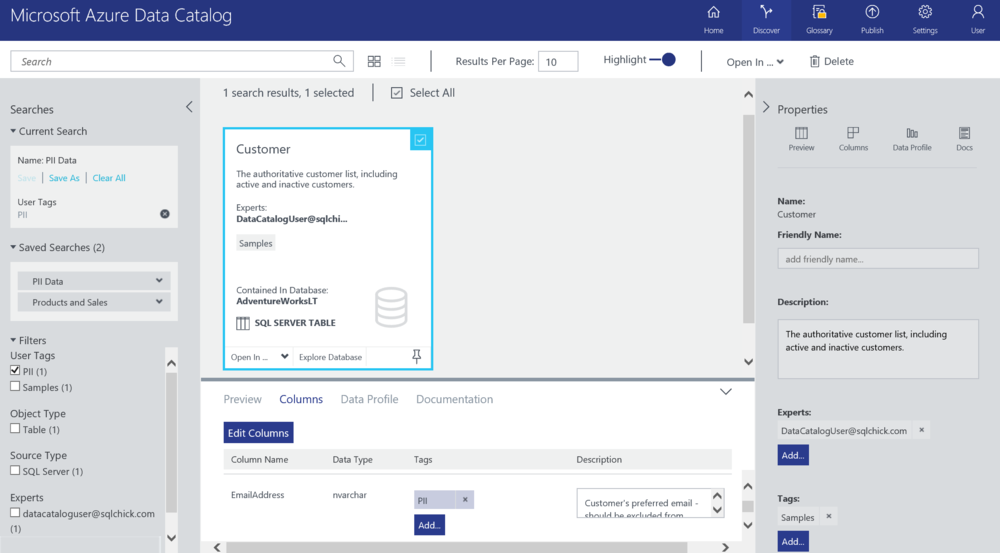
Key features
- Centralized registration of data sources across the organization.
- Crowdsourced metadata enrichment through user-contributed annotations.
- Tagging, documentation, and access procedure notes for each dataset.
- Supports structural metadata extraction and user-defined metadata.
- Simplifies BI workflows by making trusted data assets discoverable.
Pros
- Easy to use and intuitive for both technical and non-technical users.
- Encourages collaboration through shared metadata contributions.
- Lightweight and quick to set up within Azure environments.
- Improves discoverability of business intelligence data assets.
Cons
- Limited to basic metadata management. Lacks advanced lineage, profiling, or automation.
- No AI-powered discovery or recommendation features.
- Microsoft is shifting focus toward Purview for enterprise data governance.
- Better suited for small-to-medium scale use cases, not large enterprise needs.
27. DataGalaxy
DataGalaxy is a modern SaaS data catalog and knowledge platform designed with business users in mind. It combines active metadata management with a sleek user experience to engage both technical and non-technical teams. From data lineage and traceability to business glossaries and quality scoring, DataGalaxy supports a broad range of governance and discovery use cases while keeping ease of use front and center.
Its flexible architecture, 70+ native connectors, and well-documented APIs make it a strong choice for data product teams looking for automation, customization, and collaborative governance.
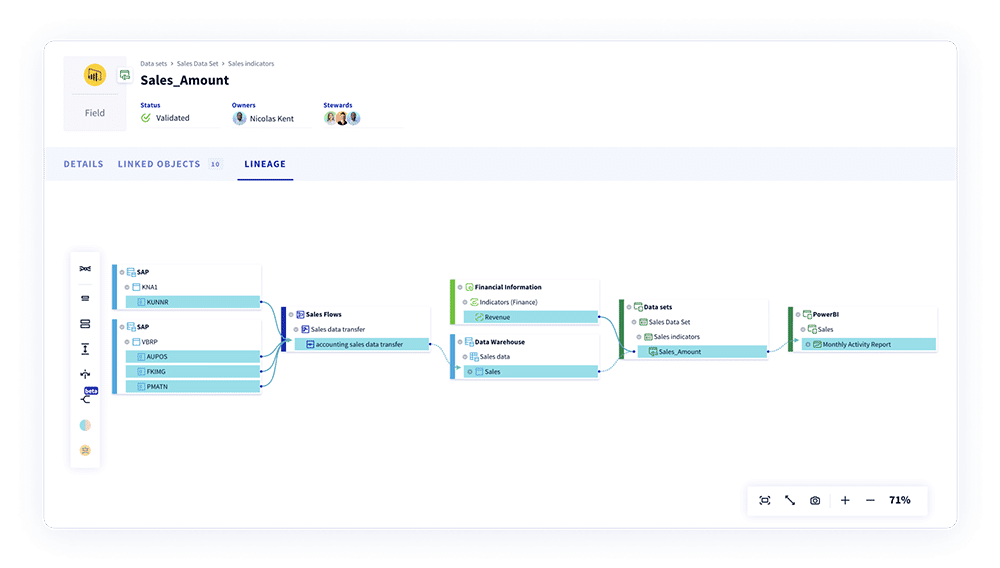
Key features
- 70+ prebuilt connectors for real-time cataloging across modern and legacy stacks.
- Metabot, an AI data steward, automates repetitive metadata tasks.
- Expandable meta-model and customizable asset layouts.
- Python SDK and open API for custom workflows and integration.
- Built-in features for data lineage, glossary, trust scoring, and traceability.
Pros
- Intuitive UI with a strong focus on business engagement.
- Automation and extensibility for technical teams.
- Strong metadata visualization and traceability features.
Cons
- Smaller market footprint compared to legacy enterprise tools.
- May require upfront effort to configure custom models and layouts.
- Some advanced governance functions may depend on API-based customization.
- Best suited for midsize to large teams with dedicated data roles.
28. Alex Augmented Data Catalog
Alex Augmented Data Catalog is an AI-driven platform that automates the discovery, organization, and governance of structured, semi-structured, and unstructured data. It consolidates data assets into a centralized catalog while offering collaborative features for data sharing and curation. With a single governance console, admins can define policies, assign stewards, and monitor data pipelines, making it easier to enforce standards and improve quality across the organization.
The platform is designed with usability in mind, offering natural language search and a plug-and-play metadata marketplace for fast integration with common data sources.
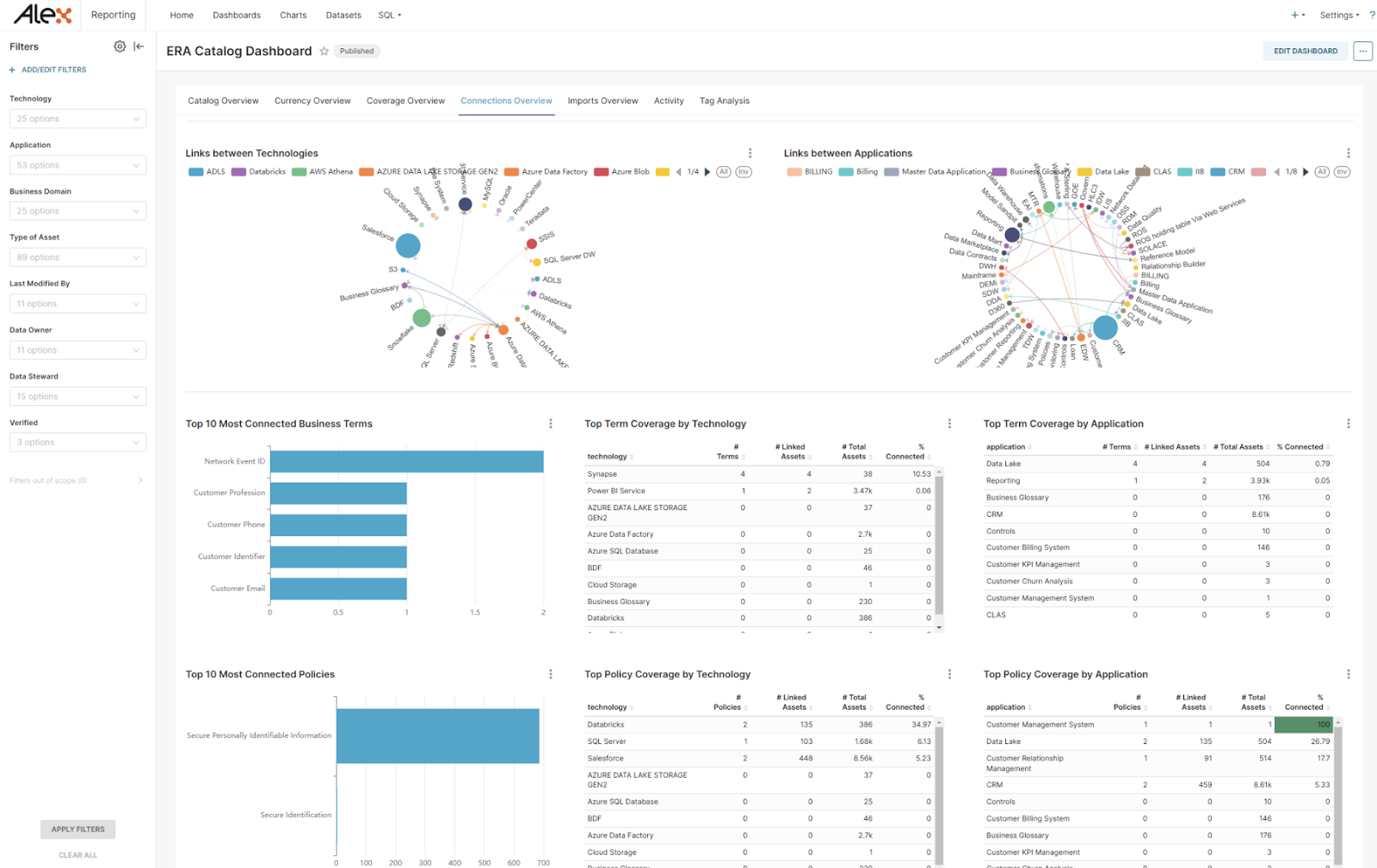
Key features
- Automated data discovery and cataloging for all data types.
- Natural language search and query interface modeled after Google.
- Unified console for governance policy management and stewardship.
- Plug-and-play metadata connectors to accelerate integration.
- Auto-enrichment of metadata for enhanced catalog context and usability.
Pros
- Strong automation features for metadata population and governance workflows.
- Easy-to-use interface for both technical and business users.
- Built-in collaboration and sharing tools for data curation.
- Rapid integration with popular data platforms via metadata marketplace.
Cons
- Less widely adopted than major open-source or enterprise catalog platforms.
- Limited visibility into ecosystem maturity and community support.
- May lack advanced observability or lineage tools found in leading solutions.
- Unknown scalability for extremely large or complex data environments.
How to choose the right data catalog tool for your company
When evaluating a data catalog tool, there are several factors you should consider. It requires a strategic approach that aligns with your organization’s data governance needs, infrastructure, and business objectives. By following a structured process, you can ensure the tool you choose effectively enhances data visibility, collaboration, and compliance.
1. Consider your needs
Start by outlining your organization’s specific data challenges and goals. Identify what you expect from a data catalog tool—whether it’s improving data discovery, enhancing governance, or ensuring compliance. Engaging with your data team and other key stakeholders will help define these priorities and narrow your selection.
- Identify key use cases: Determine if your focus is on metadata management, data lineage tracking, compliance, or collaboration.
- Engage stakeholders: Gather input from data engineers, analysts, and business users to understand their needs.
- Define success metrics: Establish measurable goals, such as improved data accessibility or reduced compliance risks.
2. Compare tools and features
Once you have a clear understanding of your needs, compare different data catalog tools based on their features and capabilities. Evaluate their ability to integrate with your existing data stack (e.g., Snowflake, BigQuery, AWS), handle large-scale metadata management, and automate key governance functions like data lineage and access control. Consider additional features beyond cataloging, such as data quality monitoring and collaboration tools, to see if they align with your business requirements. Also, keep budget constraints in mind, as costs can vary significantly between solutions.
- Assess integration capabilities: Ensure the tool supports your databases, cloud platforms, and BI tools.
- Look for automation features: AI-driven metadata tagging, data classification, and lineage tracking can reduce manual work.
- Evaluate security & compliance tools: Features like role-based access control (RBAC) and audit logs help maintain governance standards.
- Compare pricing models: Consider licensing fees, implementation costs, and the total cost of ownership.
3. Seek feedback from teams and industry peers
Before making a decision, consult your data team and other stakeholders to gather feedback on the shortlisted options. Understanding their perspectives on usability, integration, and potential challenges can be invaluable. Additionally, reach out to industry peers to learn about their experiences with different tools and get recommendations based on real-world usage.
- Consult internal teams: Ask engineers, analysts, and governance leads about usability and adoption challenges.
- Engage with industry networks: Join data governance forums or LinkedIn groups to learn from peers.
- Read case studies & reviews: Analyze how similar organizations have implemented and benefited from different tools.
4. Test the tools with demos and trials
Most data catalog providers offer free trials or demos, allowing you to test their platform before committing. Take advantage of these trials to assess ease of use, performance, and how well the tool integrates with your workflows. Ensure multiple team members participate in testing to get a well-rounded view of the tool’s effectiveness.
By following this structured approach—identifying needs, comparing options, gathering feedback, and testing solutions—you can confidently choose a data catalog tool that meets your company’s data governance goals and drives better data-driven decision-making.
Benefits of data catalog tools
A data catalog plays a critical role in modern data governance by enhancing data discovery, accessibility, and compliance. By organizing metadata and improving visibility, businesses can maximize the value of their data assets while ensuring security and governance standards are met.Effective data catalogs are more than just a repository of definitions and assets. For data catalogs to be valuable, they need to be user-friendly for both technical and non-technical users.
1. Improved data discovery and accessibility
A data catalog enables users to quickly find and understand data across an organization. With powerful search capabilities, metadata tagging, and AI-driven recommendations, teams can locate relevant datasets without manual effort.
- Centralized metadata repository: Provides a single source of truth for all data assets.
- Enhanced search and filtering: Allows users to locate data based on attributes, tags, and descriptions.
- Business glossaries: Helps non-technical users understand data in business terms.
2. Enhanced data governance and compliance
Maintaining regulatory compliance is easier with a data catalog that tracks data lineage, access controls, and policy enforcement. Organizations can ensure they meet GDPR, HIPAA, CCPA, and other regulations.
- Data lineage tracking: Ensures transparency by visualizing data transformations and movement.
- Role-based access control (RBAC): Restricts access to sensitive data based on user permissions.
- Audit logs and policy enforcement: Keeps a record of changes and ensures compliance with governance frameworks.
3. Increased data trust and quality
Data catalogs help organizations maintain high data quality by providing automated profiling, validation, and issue tracking. This builds trust in data-driven decision-making.
- Automated data profiling: Identifies inconsistencies, duplicates, and missing values.
Data certification and stewardship: Allows teams to tag and certify reliable datasets for enterprise use. - Quality score metrics: Provides insights into the reliability of datasets before use.
4. Greater collaboration across teams
By providing a shared platform for data documentation and discussion, a data catalog fosters collaboration between data engineers, analysts, and business users.
- User annotations and comments: Enables teams to document data insights and usage guidelines.
- Crowdsourced metadata management: Encourages collaboration by allowing teams to contribute context.
- Approval workflows: Ensures proper governance by validating data before use.
5. Faster decision-making and analytics
With a well-organized data catalog, teams spend less time searching for and validating data, leading to faster insights and more efficient analytics.
- Reduced time spent searching for data: Helps analysts find the right datasets instantly.
- Self-service analytics: Empowers business users to access and understand data without IT support.
- Integration with BI tools: Allows seamless connectivity with platforms like Tableau, Power BI, and Looker.
By implementing a data catalog tool, organizations can improve data governance, enhance collaboration, and drive more informed decision-making. Overall, data catalogs play an important role in enabling organizations to make better use of their data and drive insights that can help inform business decisions.
Enhance your organization’s data discovery with Secoda
Organizations looking for an all-in-one data management and data discovery tool should choose Secoda. Secoda has the data catalog features you need to organize and centralize your data, along with numerous tools for other aspects of data management. Businesses that want to easily enable self-service analytics in their organization can trust Secoda to get them there.
Why Choose Secoda?
- Centralized Data Management: Keep all your data in one place for easy access and organization.
- Enhanced Data Discovery: Quickly find the data with user-friendly search features.
- Self-Service Analytics: Enable your team to perform analytics independently without relying on others.
- Automated Metadata: Automatically manage and update metadata to keep information accurate and current.
Try Secoda today to see if our platform is right for you.
.png)
.png)








