




See why hundreds of industry leaders trust Secoda to unlock their data's full potential.
 Get the guide
Get the guideData teams today aren’t struggling with a lack of data. The real challenge is making that data easy to find, understand, and trust. As companies scale, inconsistent definitions, scattered documentation, and siloed systems make it harder to collaborate, answer questions, and maintain data quality. That’s where data dictionary tools come in.
A modern data dictionary helps teams organize and standardize how data is defined across the stack. It centralizes key metadata, improves searchability, and gives both technical and non-technical users the context they need to work with data confidently. And with automation, collaboration features, and built-in governance becoming the norm, these tools have evolved far beyond static spreadsheets.
There are a lot of options out there, and picking the right tool depends on your stack, your workflows, and how your team uses data. In this guide, we’ve rounded up the top data dictionary tools for 2025 to help you find a solution that fits, and sets your team up for long-term success.
List of data dictionary tools for 2025
AI-native & collaborative
Secoda
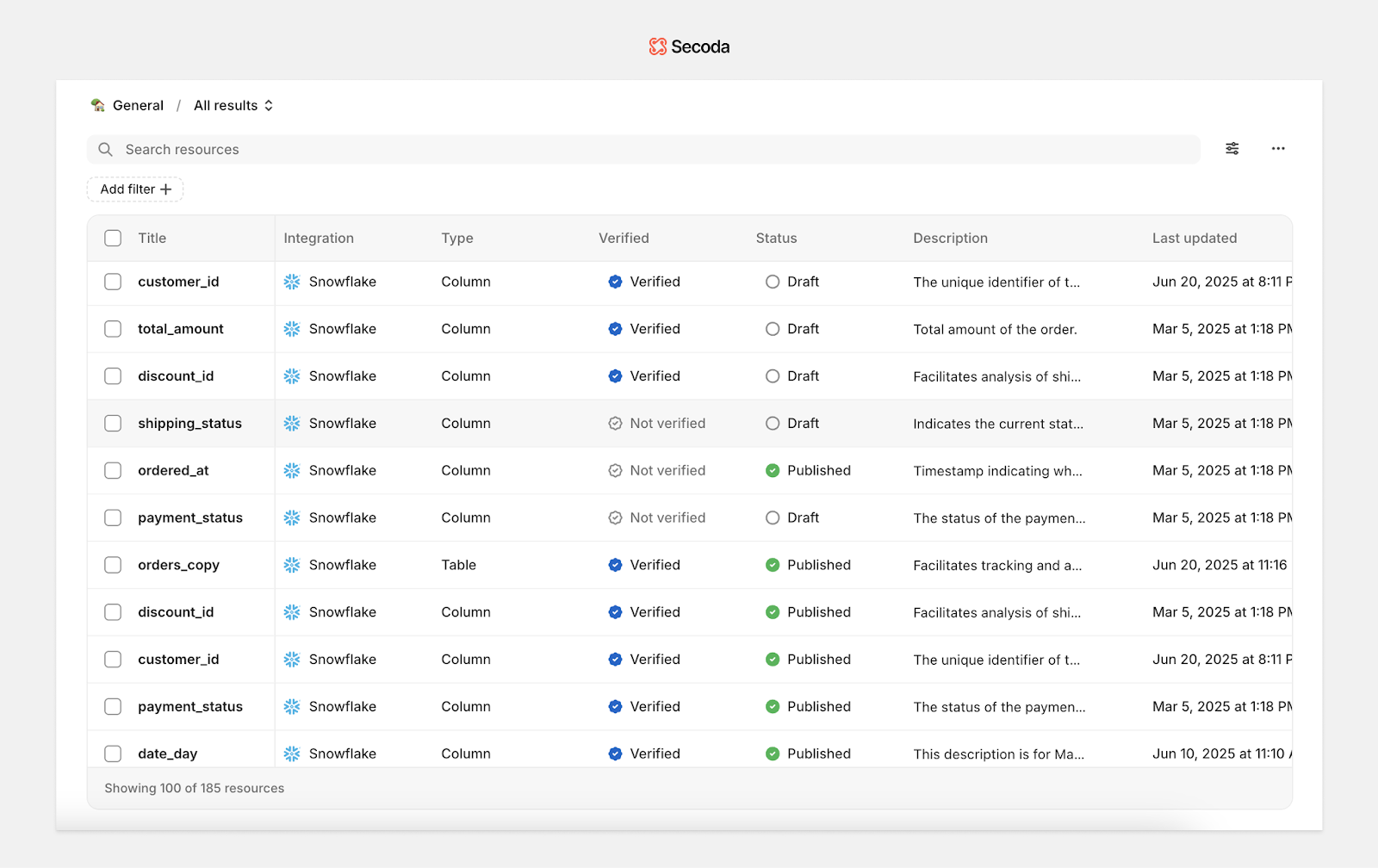
Secoda is an AI-native data management platform that combines data cataloging, lineage, governance, quality monitoring, and self-service analytics all in one collaborative workspace. Built to reduce manual overhead and improve data accessibility, Secoda automates metadata ingestion, documentation, and data dictionary creation. Its natural language search and no-code interface make it easy for both technical and non-technical users to explore, document, and trust their data.
What sets Secoda apart in 2025 is its AI-first approach to data discovery. Users can ask plain-language questions and get contextual answers, complete with visualizations, column-level lineage, and documentation without writing SQL. The platform brings structured metadata, Q&A, and business context into a single view, making the data dictionary an active source of truth.
Key features
- AI-powered search that returns contextual answers to data questions
- No-code self-serve analytics and chart generation with Secoda AI
- Automated metadata ingestion and documentation
- Built-in data quality scoring and column-level lineage
- Centralized data dictionary with 80+ native integrations
- Granular access controls with RBAC and Git-based versioning
- Collaborative workspace with Slack-style Q&A and documentation threads
Secoda’s data dictionary connects data definitions to real usage, ownership, and lineage, helping teams work faster and with more confidence. It’s especially useful for companies looking to empower non-technical users, reduce reliance on the data team, and standardize documentation across tools.
Best for: Teams that want a modern, AI-supported data dictionary that doubles as a full data management platform.
Legacy / heavyweight
Collibra
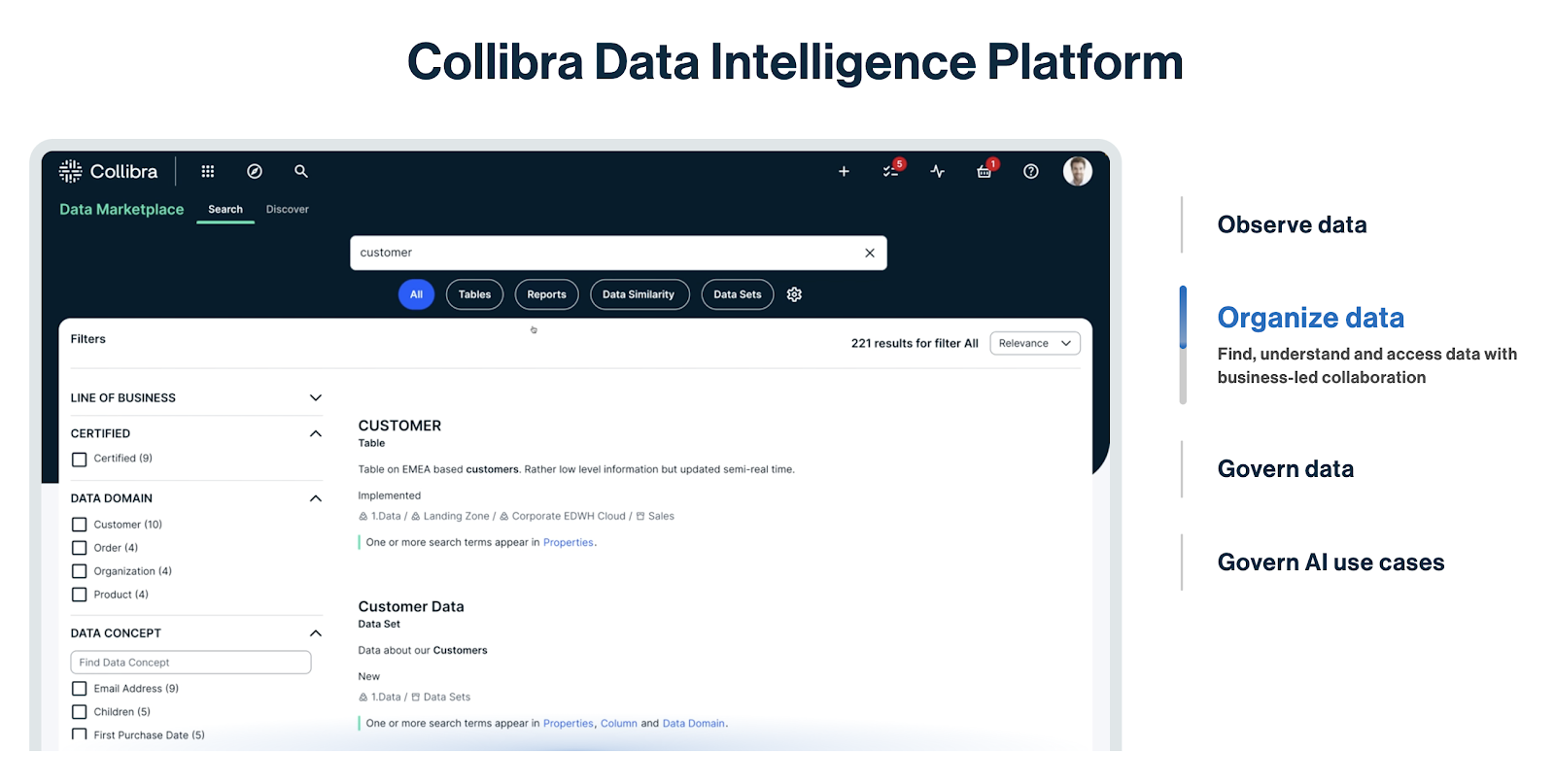
Collibra is an enterprise data governance platform that includes a robust data dictionary as part of its broader catalog and stewardship workflows. It allows teams to define, manage, and standardize business terms across systems, linking them to technical metadata and lineage for full traceability. With built-in workflows, role-based access, and integration into data quality and privacy tools, it’s designed for organizations with mature governance needs. While powerful, it can be complex to implement and is best suited for large-scale environments with dedicated data governance roles.
Best for: Enterprises that need a centralized, governed data dictionary tied into broader compliance and stewardship processes.
Talend Data Catalog
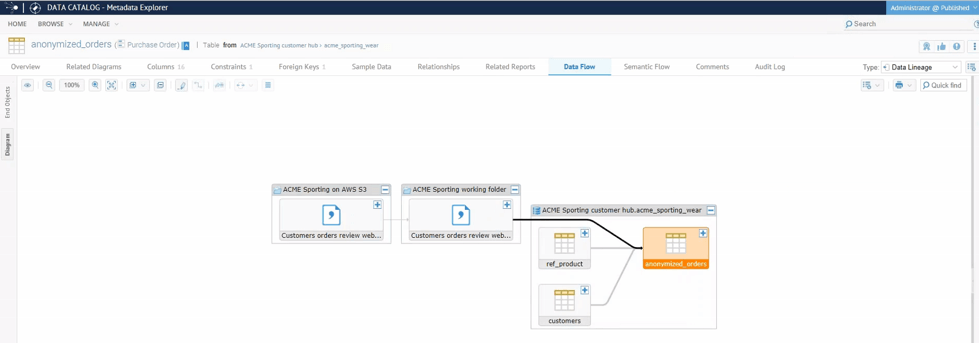
Talend Data Catalog provides a centralized repository for managing data definitions, metadata, and relationships across your data ecosystem. It automatically crawls and profiles data sources, populating a searchable data dictionary enriched with technical and business metadata. Built-in collaboration tools and role-based access controls support governance and documentation at scale. While it’s most effective when used alongside other Talend tools, it offers strong data dictionary functionality for teams focused on visibility and consistency.
Best for: Organizations looking for an automated, metadata-driven data dictionary tightly integrated with data quality and governance workflows.
Alation
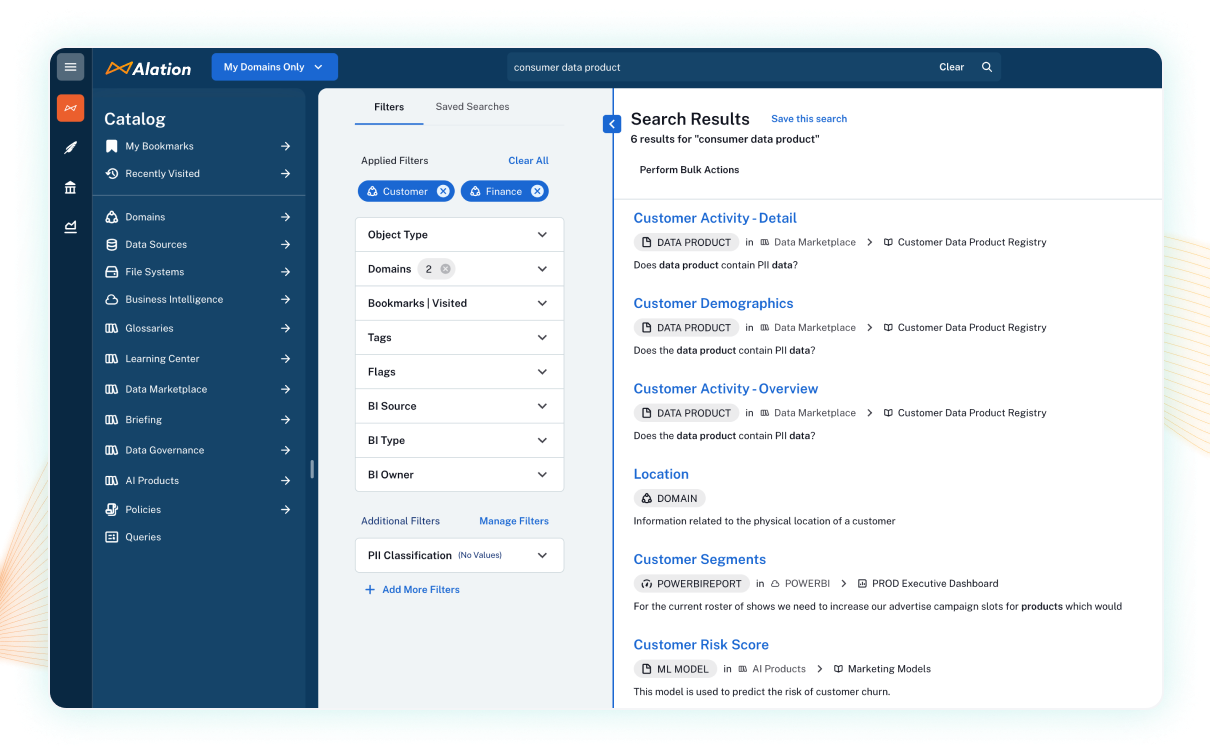
Alation offers a collaborative data catalog with a built-in data dictionary that connects business definitions to technical metadata, helping teams standardize terminology and improve data understanding. It supports automated metadata ingestion, column-level lineage, and active stewardship, making it easier to track data usage and ensure consistent documentation. Its search and governance workflows are designed to scale across large organizations. While it’s enterprise-ready, setup and customization can take time, especially for smaller or less structured teams.
Best for: Companies that need a scalable, governance-focused data dictionary built for collaboration across data, analytics, and business teams.
ER/Studio
ER/Studio by Idera is a data modeling tool that includes a built-in data dictionary for defining and managing both technical metadata and business terms. It supports enterprise glossaries, semantic mapping, and documentation of relationships across complex data environments. Teams can collaborate on definitions and track changes over time using version control and role-based access. While it’s powerful, it’s best suited for organizations with formal data modeling practices in place.
Best for: Enterprises that need a structured, model-driven approach to managing data definitions across large, distributed systems.
Microsoft Purview

Microsoft Purview is a unified data governance solution that includes a built-in data dictionary as part of its catalog and metadata management tools. It automatically scans data sources across your Azure and hybrid environments, populating business and technical metadata for easy search and classification. Users can define terms, track lineage, assign ownership, and apply policy. While it’s deeply integrated with the Microsoft ecosystem, it may be less flexible for teams using a more diverse stack.
Best for: Organizations already in the Azure ecosystem looking for an automated, governance-ready data dictionary with strong lineage and classification support.
Data modeling + dictionaries
erwin Data Modeler
Erwin Data Modeler is an enterprise-ready data modeling platform that helps teams document, standardize, and manage data definitions at scale. Its built-in data dictionary features support both business and technical metadata, making it easier to define terms, track data structures, and maintain consistency across systems. The platform automates schema discovery, supports metadata versioning, and connects with data governance workflows to keep documentation up to date. While powerful, it’s best suited for organizations with complex data environments and dedicated governance teams.
Best for: Enterprises looking for a robust, standards-driven approach to managing data definitions and metadata.
DbSchema
DbSchema is a visual database designer that includes built-in data dictionary tools for documenting and managing metadata across SQL and NoSQL databases. It lets users create interactive diagrams, annotate tables and columns, and generate HTML or PDF-based data dictionaries for easy sharing. With features like schema synchronization and offline modeling, it’s useful for teams managing multiple database environments. While not a full governance solution, it’s a practical choice for developers and analysts who need lightweight, flexible documentation.
Best for: Teams that want visual schema documentation and an easy way to generate and share data dictionaries across environments.
Vertabelo
Vertabelo is a browser-based data modeling tool that allows teams to create and manage data dictionaries as part of their database design process. It supports logical and physical modeling, lets users define and document tables, columns, and relationships, and offers version control to track changes over time. Data dictionaries can be shared via exports or links, making it easy for teams to collaborate. While it’s more modeling-focused than governance-oriented, Vertabelo works well for organizations looking to embed documentation directly into their design workflows.
Best for: Teams that want built-in data dictionary support within a cloud-based modeling tool that’s easy to share and maintain.
Lightweight / SQL-first
Dataedo

Dataedo is a desktop-first documentation tool built specifically for creating and maintaining data dictionaries. It connects to your databases, extracts metadata, and lets teams annotate tables, columns, and relationships with business-friendly descriptions. With support for ER diagrams, data lineage, and export to HTML or PDF, it's ideal for teams that want structured, portable documentation without complex setup. While it lacks broader governance features, it’s a reliable choice for organizations focused on clarity and consistency in data definitions.
Best for: Teams that need a standalone data dictionary tool with strong export options and minimal overhead.
Open-source & cloud-native
Apache Atlas

Apache Atlas is an open-source metadata and governance framework designed for managing data across Hadoop and other big data platforms. It includes data dictionary features that allow users to define and manage technical metadata, business terms, and classifications. Atlas also supports automated lineage tracking, tagging, and access policies. While powerful and highly customizable, it requires engineering resources to set up and maintain, making it a better fit for technically mature teams.
Best for: Engineering-led teams working in Hadoop or hybrid data environments who want an open-source, extensible data dictionary and governance framework.
Google Cloud Data Catalog (Dataplex)
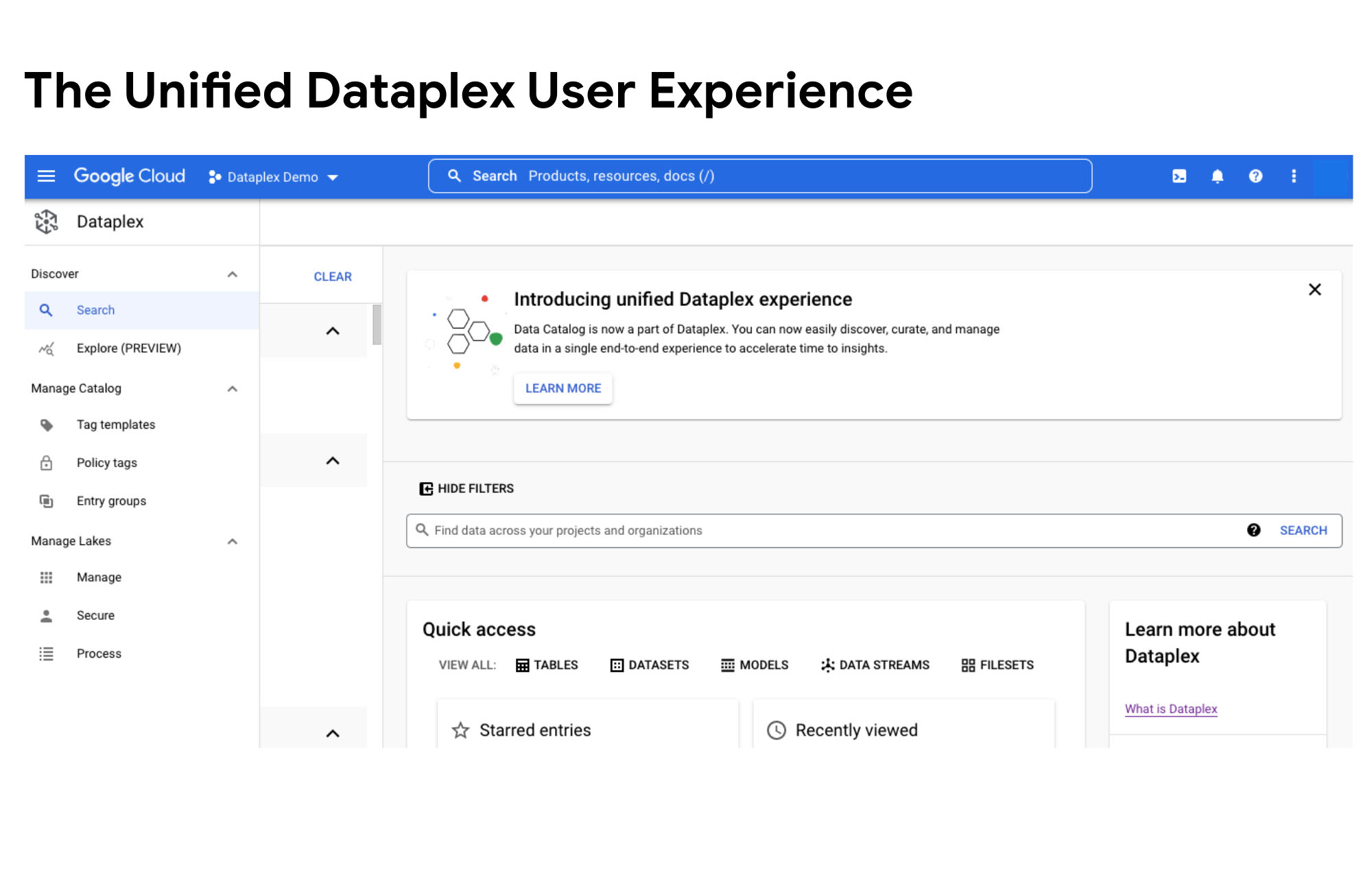
Now integrated into Dataplex, Google Cloud’s Data Catalog offers automated metadata discovery, tagging, and data dictionary capabilities across BigQuery, Looker, Pub/Sub, and more. It allows teams to define business terms, attach custom tags, and manage metadata centrally, with built-in support for policy enforcement and access controls. Its tight integration with the broader Google Cloud ecosystem makes it easy to maintain consistent documentation and governance at scale. That said, it's most effective for teams already standardized on GCP.
Best for: Teams operating on Google Cloud that want an automated, native data dictionary with strong metadata tagging and governance features.
Amundsen (by Lyft)
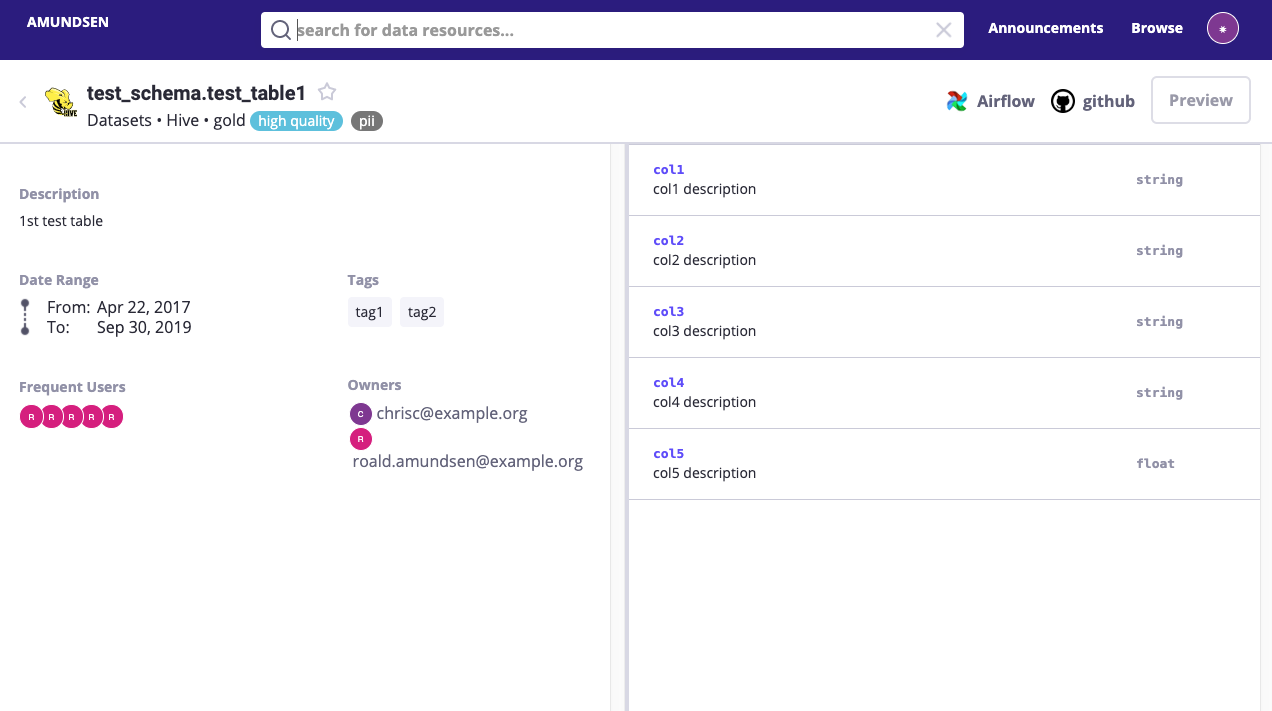
Amundsen is an open-source data discovery and metadata platform built to help teams surface and document data assets across modern data stacks. It includes a lightweight data dictionary where users can define terms, add descriptions, and track data ownership backed by automated metadata ingestion and search. It also surfaces usage stats and lineage to give context to documentation. While it’s developer-friendly and highly extensible, it requires engineering support to deploy and maintain.
Best for: Modern data teams looking for a lightweight, open-source data dictionary that integrates well with tools like Airflow, Snowflake, and dbt.
DataHub (by LinkedIn)
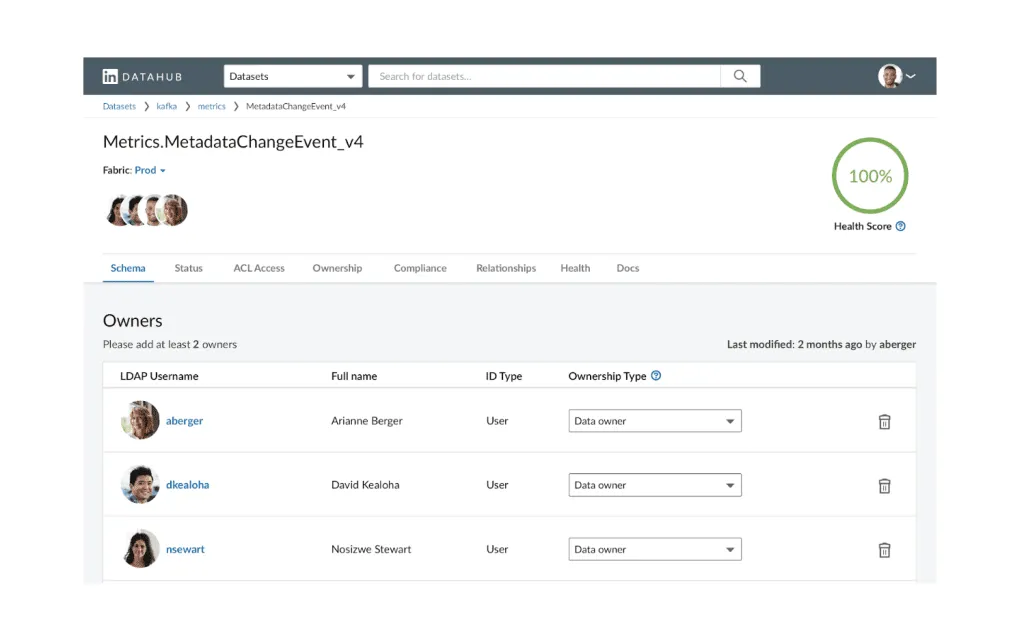
DataHub is an open-source metadata platform developed by LinkedIn that offers a dynamic, real-time data catalog with built-in data dictionary capabilities. It automatically captures and displays metadata, lineage, ownership, and usage metrics across modern data tools. Teams can define business terms, add documentation, and track schema changes all in a searchable, API-friendly interface. While powerful and flexible, it requires engineering effort to set up and customize.
Best for: Engineering-driven teams that want a flexible, open-source data dictionary tightly integrated with their metadata and lineage systems.
Why data dictionary tools matter
A data dictionary is a centralized source of truth for your data. They define fields, metrics, formats, and relationships in a way that anyone on your team can understand. It gives structure to your metadata, so teams spend less time guessing what a column means and more time actually using the data.
Modern data dictionary tools take this further by automating documentation, making metadata searchable, and linking definitions to actual usage across tools. The result? Better data quality, faster insights, and clearer communication across teams.
Key benefits of data dictionary tools:
- Organize and manage data more effectively
With a well-maintained dictionary, teams can spot patterns, understand relationships, and find what they need without digging through siloed systems. - Enable faster, more confident analysis
Clear definitions and consistent context help teams move faster without second-guessing what a metric means or who owns it. - Improve accuracy and reduce confusion
Standardizing definitions across teams reduces errors and improves data integrity, especially when multiple people or tools touch the same data. - Make metadata searchable and accessible
When your data is documented and easy to search, it's easier for everyone to understand and use, whether they’re in engineering, analytics, or operations.
Data dictionaries are no longer static documents. Today’s tools bring automation, version control, and collaboration into the process. This makes it easier to keep your documentation accurate, up-to-date, and useful across your entire stack.
How to choose the right data dictionary tool for your company
When choosing a data dictionary tool, it’s important you find the right fit for your stack, your team, and how your organization works with data. Here are some considerations when evaluating tools.
Step 1: Identify what your team actually needs
Start by getting input from the people who will use the tool most: your data team, analysts, and key stakeholders. Figure out what problems they’re trying to solve. Is it centralizing documentation? Automating metadata? Making data easier to find for non-technical users?
Step 2: Narrow your list based on core capabilities
Focus on tools that support the features that matter most to your use case. Some of these features to consider are automated metadata capture, glossary management, lineage, search, tagging, and AI-powered documentation.
Step 3: Check compatibility with your stack
Make sure the tools you’re considering integrate smoothly with your existing data sources, like your data warehouses, BI tools, transformation layers, and orchestrators. The less manual setup, the better.
Step 4: Evaluate usability and adoption potential
Your tool won’t deliver value if no one uses it. Prioritize tools with a clean interface, intuitive workflows, and built-in collaboration features. Bonus points if they work well for both technical and non-technical users.
Step 5: Prioritize security and scalability
Choose a platform that keeps your data secure. Look for enterprise features like SOC 2 compliance, role-based access, and audit logs. And make sure it can scale with your team as data volume and complexity grow.
Why choose Secoda for your data dictionary needs?
Secoda stands out as a comprehensive AI-powered platform that brings together your documentation, metadata, lineage, and quality monitoring in one place. It’s built for teams that want to reduce manual work, move faster, and make data easier to understand across the company.
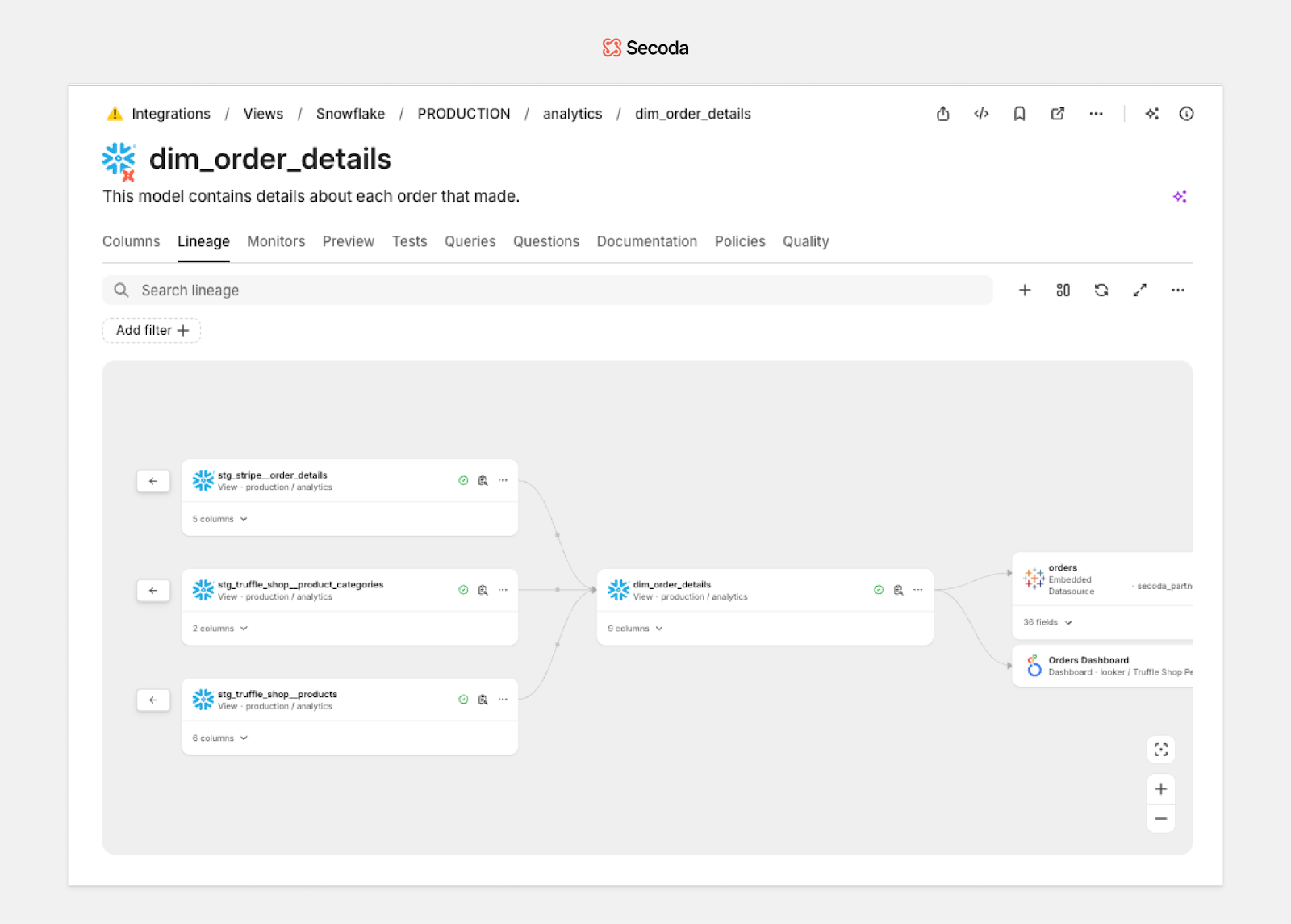
Here’s what you can expect when you choose Secoda:
- Centralized, searchable data definitions
Keep all your metrics, terms, and documentation in one place. Fully searchable and easy to maintain. - Automated metadata and documentation
Automatically ingest metadata from 80+ tools so your documentation stays accurate without manual updates. - Built-in column-level lineage and quality insights
Understand where your data comes from, how it’s used, and whether it’s passing quality checks, all from one view. - AI-powered search and natural language querying
Ask Secoda AI about a term, table, or dashboard and get contextual answers without writing SQL. - Collaboration without friction
Assign ownership, track changes, and document questions in a shared workspace that feels intuitive across teams. - Secure and scalable
Role-based access controls, version history, and flexible pricing plans make it easy to grow without adding overhead.
If you want a data dictionary that stays up to date, connects to the rest of your stack, and makes data easier for everyone to use, Secoda is built for that. Try it free and see how fast your team can move when documentation works with you, not against you.
.png)
.png)








