



Meet the only AI assistant built for data. Analyze, document, and answer any data question — fast.
 Learn more
Learn moreMost AI tools today are built to answer general-purpose questions. But data teams need more than that. They need accurate, governed, and explainable answers, often in high-stakes environments where context matters and access controls can't be ignored. That’s why we built Secoda AI not just as a chatbot, but as an AI-powered governance assistant designed specifically for the modern data stack.
Secoda AI helps teams understand, maintain, and act on their data through tightly integrated search, lineage, documentation, and quality workflows. Under the hood, it's powered by a hybrid model strategy, a multi-agent architecture where specialized agents collaborate on complex tasks, a multi-layered RAG architecture, and a toolset purpose-built for data practitioners. Whether you're debugging a SQL error, documenting a new source, or tracing upstream dependencies, Secoda AI shows its work, respects your permissions, and links back to source.
This guide walks through the technical foundation behind Secoda AI including the models we use, the way we retrieve and assemble context, how we ensure trustworthy outputs, and the tooling that turns answers into action.
Let’s dive in.
What models power Secoda AI?
When we set out to build Secoda AI, we knew that relying on a single model wouldn’t cut it. Data governance tasks demand precision, context, and reasoning, but also speed and cost-efficiency. That’s why Secoda AI takes a hybrid model approach, dynamically switching between multiple large language models depending on the complexity of the task.
We use multiple AI models optimized for different types of data tasks, including Claude Opus and Sonnet 4 from Anthropic. We’ve engineered a system that starts with the most capable model for reasoning and falls back to lighter-weight models for routine follow-ups. Combined with custom prompt engineering and fallback logic, this setup helps us optimize for accuracy, speed, and cost, all at once.
Below, we’ll break down the reasoning behind our model choices and how each one fits into the broader Secoda AI workflow.
1. What models power Secoda AI today?
Our system intelligently routes tasks to the most appropriate model across Anthropic's latest models.
2. How does model switching work?
Our multi-model orchestration allows us to apply the right level of power at the right moment, and forms the foundation for our multi-agent orchestration where specialized agents collaborate on complex tasks while sharing the same intelligent model routing strategy.
3. What happens if a model hits a rate limit or fails?
Secoda AI includes a fallback architecture:
- Automatically switches models when rate limits are hit or service errors occur
- Uses Anthropic’s cache optimization to improve response times for repeated queries
- Performs context filtering when token limits approach, preserving only what’s most relevant
How does Retrieval-Augmented Generation (RAG) power Secoda AI?
Secoda AI uses Retrieval-Augmented Generation (RAG) to generate answers that are grounded in your real data environment, not just model memory. By combining intelligent query understanding, targeted retrieval, and permission-aware context assembly, it delivers precise, reliable responses tailored for data governance workflows.
To answer questions about data, you need to know where it lives, how it flows, who owns it, and what it means in a specific business context. That’s why Secoda AI is powered by a deeply integrated RAG system, purpose-built for data governance.
Instead of relying solely on model memory, Secoda AI uses a multi-layered RAG pipeline that finds and delivers the most relevant context for every query. It starts by detecting intent, determining whether the question references specific assets or requires broader semantic search. Based on that, it retrieves the right mix of entity metadata, lineage relationships, usage stats, and documentation, then builds a structured, token-efficient prompt, all before generating a response.
The result is a system that delivers trustworthy, richly detailed answers, with source citations and permission-aware context filtering built in by default.
Let’s take a look at how it works under the hood.
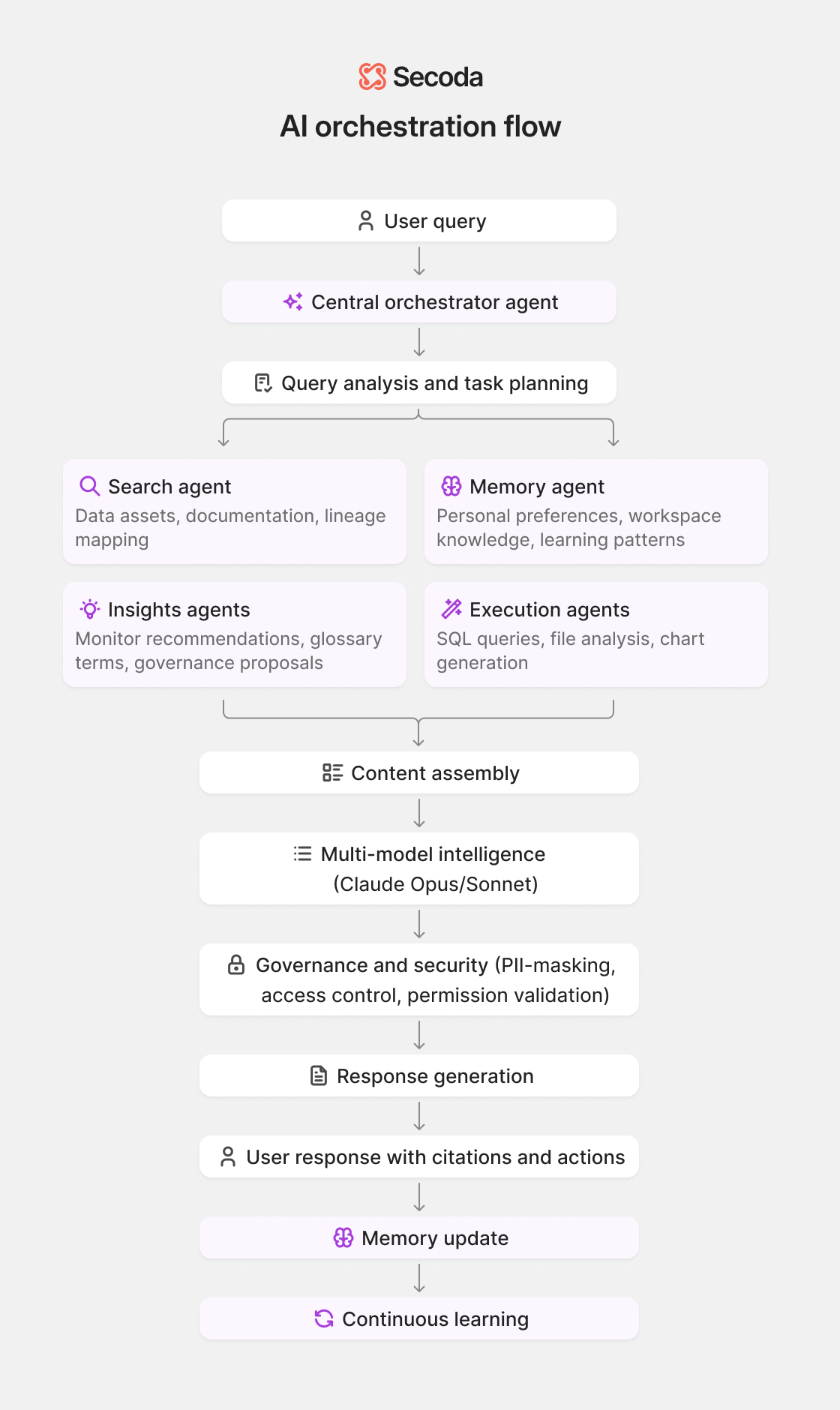
1. What’s the flow behind how RAG works in Secoda AI?
The flow looks like this:
Secoda AI uses an intelligent retrieval system designed specifically for data governance workflows. Here's the high-level flow:
Query Understanding: The system first analyzes your question to understand whether you're asking about specific data assets or need broader discovery across your catalog.
Smart Retrieval: Based on your query, Secoda AI retrieves the most relevant information from your data catalog, including metadata, documentation, lineage relationships, and usage patterns.
Context Assembly: The system assembles a focused set of information tailored to your question and permissions, ensuring you only see data you're authorized to access
Grounded Response: Using this context, Secoda AI generates responses that are directly tied to your actual data assets, complete with links back to source entities for verification.
For complex workflows, Secoda AI can coordinate multiple specialized AI agents to deliver comprehensive answers while maintaining accuracy and traceability throughout.
This approach ensures every response is grounded in your real data environment rather than relying on general knowledge or assumptions.
2. What powers the search and retrieval layers?
- Hybrid search stack: Secoda uses a combination of keyword search (for direct matches) and semantic embedding search (for broader queries).
- Secoda’s vector storage: Used for storing and querying embedding vectors efficiently. Normalized scores help ensure the best match always surfaces.
3. How does context get assembled?
Our smart context builder selects only what’s necessary:
- Descriptions
- Owners
- Tags
- Usage stats
- Lineage links
- Relevant documentation
This keeps the input tight and focused, improving both accuracy and speed, while respecting token constraints.
4. What makes Secoda’s RAG permission-aware?
Every retrieval query respects entity-level permissions. If a user doesn’t have access to a table, view, or dashboard, that entity is excluded from the context.
PII masking and persona filters help ensure users don’t see sensitive data or irrelevant metadata.
5. How does RAG change based on the user?
Secoda AI adjusts the context based on the user’s persona (e.g., analyst, engineer, business user). Different personas may see different metadata, fields, or tool recommendations, all controlled by workspace-level governance rules.
6. Where does RAG show up in the product?
RAG is used across multiple workflows:
- SQL error correction: Uses RAG to provide table schema context for query fixes
- Documentation generation: Builds docs by combining entity metadata with structured formatting
- Search result enhancement: Adds rich metadata context behind every result
How does Secoda AI ensure accuracy and reliability in its responses?
Secoda AI maintains trustworthy performance through a combination of rigorous evaluation, permission-aware retrieval, and verification-based prompting. Every response is backed by real-time validation, automated quality checks, and continuous feedback loops that fine-tune the system to your actual data environment.
In data analysis, a wrong answer can do real damage, whether it’s misclassifying sensitive data, pointing to the wrong lineage path, or suggesting invalid access changes. That’s why Secoda AI is engineered to prioritize accuracy, reliability, and traceability in every response.
Secoda AI is more accurate than prompting a general-purpose LLM because it combines advanced prompt engineering, specialized tools, and intelligent model orchestration designed specifically for data governance tasks.
Here’s how we’ve built a system you can trust.
1. What training data or feedback do we use?
Secoda AI continuously improves through a combination of real-time feedback, automated evaluation, and analysis of data governance-specific interaction patterns.
Automated feedback collection
Users can provide real-time feedback on each AI response using a granular system that captures both sentiment (positive or negative) and specific quality indicators such as "accurate," "out of date," or "too long." This feedback is logged and used to assess model performance over time.
Structured benchmarking
Every AI response is automatically benchmarked using evaluation scores on a 0–10 scale. These evaluations help track response quality and consistency across deployments and updates.
Conversation history analysis
Secoda analyzes tool usage patterns, success and failure rates, and instances of missing context within conversations. This data helps identify where the AI succeeds, where it struggles, and how to optimize future responses.
Context enrichment
Secoda incorporates quality-related signals such as data quality scores, stewardship activity, and governance patterns to provide richer context during retrieval and generation.
This combination of feedback loops and domain-specific signals ensures Secoda AI gets smarter, more relevant, and more reliable over time.
2. How do we evaluate AI response quality?
Secoda AI uses a structured evaluation framework to monitor and improve response quality over time. This includes a combination of automated scoring, continuous testing, and performance tracking. The system evaluates key aspects of each response to ensure outputs are accurate, relevant, and helpful, supporting reliable performance across a wide range of data governance tasks.
Automated CI/CD evaluation
Every code change to the platform triggers an automated test suite that evaluates AI responses using standardized prompts. This ensures consistent performance and prevents regressions before changes are deployed.
Continuous monitoring
Secoda also performs real-time monitoring across customer workspaces:
- Feedback aggregation surfaces documentation gaps and blind spots based on user interactions.
- Performance tracking monitors tool usage patterns, duration metrics, iteration counts, and success rates.
- Quality regression detection uses automated alerts to flag any drops in response quality, allowing for fast diagnosis and resolution.
Together, these mechanisms ensure that Secoda AI maintains high accuracy, consistency, and trustworthiness at scale.
3. How do we prevent hallucinations?
Secoda AI uses a multi-layered system to reduce hallucinations and ensure trustworthy, verifiable responses:
Verification-first approach
- Prompts require the model to confirm the existence of data assets before making claims
- Avoids speculative answers by grounding responses in real context
Source citation requirements
- All answers must include markdown links to actual entities in the workspace
- Explicit source attribution is included to support traceability
Iteration warnings and complexity estimation
- Built-in checkpoints detect when too many steps occur without resolution, prompting model reflection
- Upfront complexity scoring helps select the right model and limits the number of reasoning steps
Real-time validation
- Tool-based verification ensures the AI uses actual SQL execution or metadata retrieval rather than relying on assumptions.
- Progressive validation builds multi-step queries incrementally, testing key assumptions along the way.
- Error boundary handling gracefully catches failures and switches strategies if a tool returns unexpected results.
- Context boundary enforcement clearly separates verified information from reasoned inferences, reducing the chance of misinterpretation.
Quality assurance measures
- A message limit warning alerts users after 10 exchanges in a thread, reminding them that accuracy may decline with extended context chains.
- Automated benchmarking evaluates each response for factual correctness and missing context.
- User feedback integration ensures that corrections and negative ratings feed directly back into model evaluation and prompt refinement.
This foundation makes Secoda AI one of the most trustworthy governance assistants on the market tuned for fast, correct, explainable, and permission-aware responses.
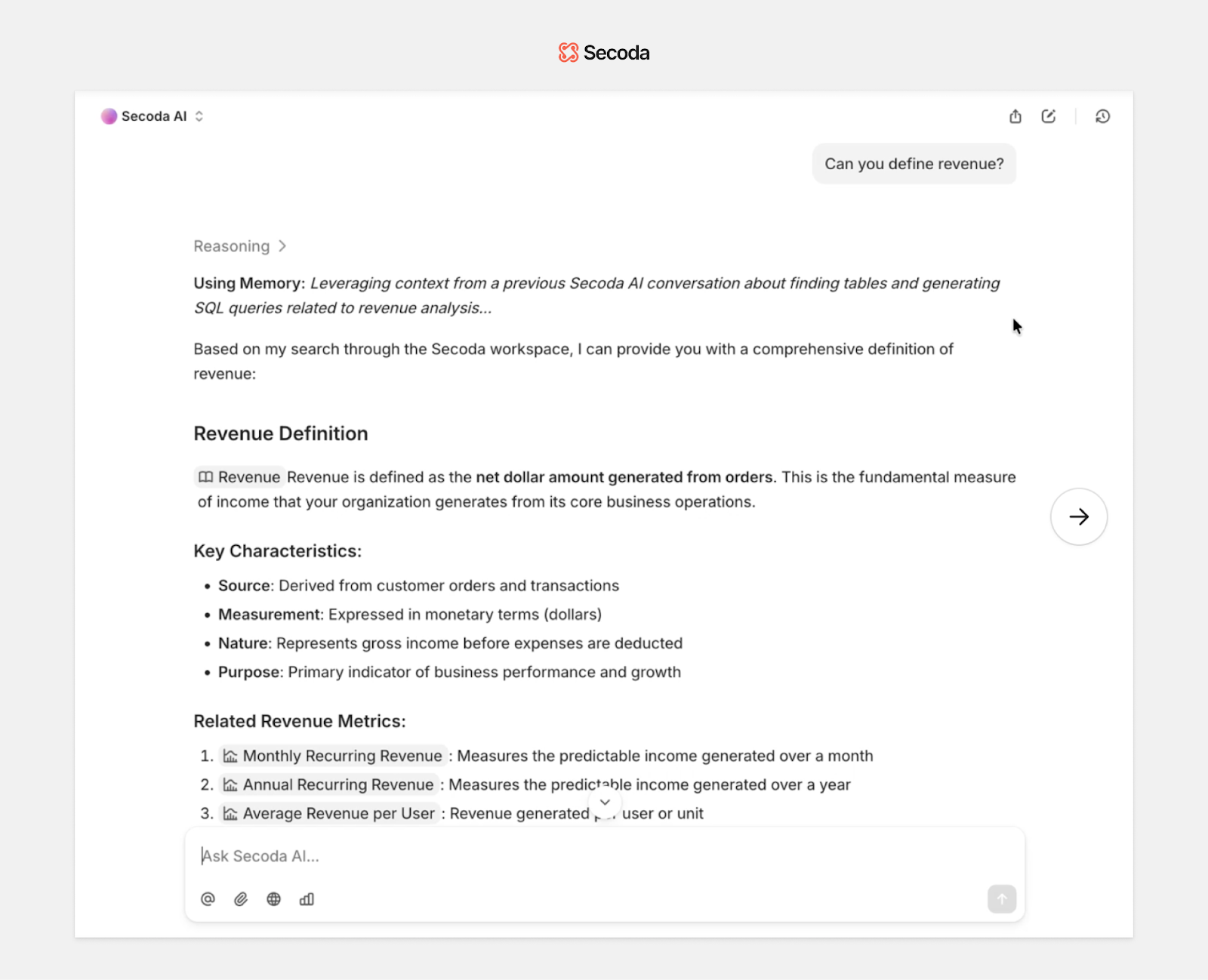
How does memory work in Secoda AI?
Secoda AI includes a built-in memory system designed to support long-term reasoning, reduce repetition, and improve accuracy over time. It does this through two layers of memory: one for individuals, and one shared across the workspace. This system enables Secoda AI to recall relevant context, reuse effective workflows, and build on prior conversations without compromising control or clarity.
Here’s how memory works in Secoda AI.
1. What types of memory does Secoda AI support?
Secoda AI maintains two distinct types of memory:
- Personal memory: Notes that each user saves for themselves, including preferences, instructions, and quick facts.
- Workspace memory: Lessons the AI learns from all conversations in the workspace, such as which tool sequences work best or how common issues are resolved.
2. What exactly gets stored?
Personal memory includes:
- User-defined instructions
- Preferences or shortcuts
- Saved context or reminders
Workspace memory includes:
- Commonly successful tool paths
- Fixes for recurring issues (e.g., dbt or SQL errors)
- Reasoning strategies that have worked across users
3. How is memory organized?
Memory is organized at two levels:
- Per-user layer: A private memory space for each individual
- Per-workspace layer: A shared knowledge base available to everyone in the organization
4. Who updates memory?
- Personal memory is manually controlled by the user who can add or delete entries themselves.
- Workspace memory is maintained by an AI agent that monitors conversations and automatically refreshes shared tips based on patterns and outcomes.
This makes the system a hybrid model, combining human-curated and AI-curated memory.
5. Does memory affect search results?
Memory does not change the order of search results. Instead:
- The AI reads memory first to determine the most effective tool plan.
- It may skip unnecessary steps or reuse workflows that have worked in similar cases.
- This results in faster, more relevant answers.
6. How is memory kept fresh?
The AI agent continuously monitors recent interactions:
- Adds new patterns and solutions
- Replaces outdated guidance
- Skips duplicates or already-learned behaviors
This memory agent represents one example of our multi-agent approach, where specialized agents handle distinct functions while contributing to the overall system intelligence.
7. How can users see when memory is in use?
When saving or deleting a personal note, users will see a quick confirmation like “Adding memory…” or “Deleting memory…”
Users can open the My Memory modal to view, review, or manage their personal notes.
How do AI queries flow through Secoda?
Secoda AI routes every query through a dynamic pipeline that analyzes the question, loads relevant permissions, selects the best model, and activates internal tools like semantic search, SQL generation, and lineage graph traversal. This adaptive process ensures that each response is generated using real-time, workspace-specific context. It also ensures it's grounded in metadata, enriched with lineage, and personalized to the user’s role.
Behind every AI response in Secoda is a real-time pipeline designed for precision, security, and speed. The moment a user types a question, Secoda orchestrates a complex set of steps that include workspace permissions, model selection, dynamic context building, and metadata enrichment to generate a trustworthy answer.
The system is designed to adapt to the user’s intent, persona, and workspace configuration. That means every interaction is grounded in accurate data, enriched with relevant context like lineage and metadata, and routed intelligently based on what the user is actually trying to do.
Here’s how that all comes together under the hood.
1. What is the typical flow when a user asks a question to Secoda AI?
Every query to Secoda AI passes through a multi-step architecture built to dynamically respond based on user intent:
- Query initialization: When a question is asked, Secoda immediately sets up context by loading workspace permissions, persona filters (e.g. business user, engineer), and governance-aware RAG filters that determine what information is allowed to be retrieved.
- Tool preparation: Secoda activates specialized internal tools built for tasks like metadata lookup, lineage traversal, and SQL generation. For complex tasks requiring specialized expertise, the main orchestrator delegates specific subtasks to purpose-built agents - search agents for comprehensive data discovery, memory agents for learning from past interactions, and suggestion agents for governance recommendations - each sharing context and results.
- Model orchestration: We pick the best-of-breed model model for first-turn reasoning and complex requests, while lighter models are used for faster follow-ups. Secoda chooses the model dynamically based on the interaction.
- Search vs. generation: The system then decides whether to search, generate, or do both - defaulting to a hybrid approach for most queries.
- Tool routing: If search is required, Secoda selects from its available search tools (semantic search, lineage graph, metadata index, etc.) based on query content.
- Retrieval & context building: Results are passed through a multi-layer RAG pipeline, where context is semantically ranked, expanded, and normalized to provide a high-quality grounding set.
- Answer generation: Finally, a relevant, workspace-specific answer is generated and streamed back to the user in real time.
2. How does Secoda decide when to use search, generation, or both?
Secoda makes this decision based on the structure and intent of the query:
- If the question has a clear factual answer (e.g. “What is the owner of this table?”), search is prioritized.
- If the question requires reasoning or transformation (e.g. “Can you rewrite this SQL to exclude PII columns?”), generation is prioritized.
- For most queries, Secoda uses both search and generation, combining relevant context from the workspace with natural language reasoning to deliver accurate, grounded answers.
3. Where does metadata or lineage fit into the flow?
Metadata and lineage are deeply embedded in both the retrieval and generation phases:
- Automatic lineage inclusion: When entities are mentioned, Secoda fetches their upstream and downstream lineage relationships in real time.
- Query-time SQL lineage: If a SQL snippet is referenced, lineage is extracted during query execution to inform the response.
- Context enrichment: Lineage paths, entity relationships, descriptions, and metadata properties are added directly to the RAG context before generation.
- Real-time freshness: Metadata is pulled live from connected tools, ensuring users see the most current information.
- Custom properties: Tags, classifications, and team-defined metadata are included to reflect workspace-specific logic.
- Integration metadata: Source-specific details (e.g. Snowflake schema, Looker view) are added where applicable.
4. Where do automations and RAG pipelines fit in?
Automations and RAG pipelines play an essential role in scaling and enriching AI responses:
- Background automations: Secoda runs entity enrichment jobs in the background to pre-process metadata, apply tags, and identify governance violations.
- Persona-aware filtering: Governance filters are automatically applied based on the user’s role and access level.
- Memory and usage signals: The system uses past workspace interactions to inform what context is most relevant in the current session.
- RAG pipeline: Context is received, ranked, expanded, and normalized in multiple layers before being passed to the LLM.
How does Secoda AI protect customer data?
Secoda is built with privacy-first AI features that ensure customer data remains secure, compliant, and isolated at every stage of the AI pipeline. All AI interactions are governed by workspace-level permissions, data classifications, and configurable privacy settings.
Here’s how privacy and data security are enforced in practice.
Built-in privacy controls
- Automatic PII masking: Data marked as PII is automatically redacted from AI responses using built-in masking tools.
- Workspace isolation: AI operates strictly within each customer’s workspace and only accesses information permitted by the user’s role and permissions.
- Governance-aware responses: AI uses classification and access rules to ensure that only authorized data is included in any response.
- Configurable access: Organizations can define what types of data the AI has access to through workspace-level settings.
Data handling safeguards
- Query result sanitization: SQL query results are processed to remove or mask sensitive values before being passed to the AI system.
- Context filtering: Any content the user isn’t authorized to see is automatically excluded from the AI prompt.
- Audit logging: Every AI interaction is logged for traceability, compliance reviews, and internal monitoring.
AI model training and data handling
- No training on customer data: Secoda does not use customer prompts or data to train AI models.
- Vendor separation: When using third-party models like Anthropic, interactions are governed by strict license agreements that include data protection terms.
Inference architecture
Secoda uses a hybrid approach to inference:
- External inference: Third-party models run on their own infrastructure, accessed securely through APIs.
- Internal processing: Embedding generation, context building, masking, and SQL execution happen within Secoda’s infrastructure.
- Data minimization: Only the minimal, necessary context is sent to external models. Sensitive operations remain fully within Secoda’s systems.
What makes Secoda AI different?
Most AI tools in the data space rely on generic models that require extensive prompting and manual context-setting. Whether you’re using ChatGPT or embedded copilots, these tools often lack awareness of your data stack, governance policies, and team workflows.
Secoda AI is built differently. It’s a data-native copilot designed specifically for data and governance use cases, with deep integration into your metadata, schema, and lineage. Every response is informed by your connected systems, your governance rules, and your users’ roles.
Here’s what sets it apart.
1. What makes Secoda AI unique vs. using ChatGPT or Copilot tools?
Secoda AI is not a general-purpose chatbot. It’s a purpose-built governance assistant that deeply understands your data environment. Key differentiators include:
- Data-native intelligence: Secoda AI is built specifically for data governance workflows, with deep understanding of metadata, lineage, and governance concepts.
- Purpose-built tools: From SQL execution to lineage traversal and file analysis, Secoda AI has built-in capabilities designed for real-world data workflows.
- Multi-agent coordination: When tasks require specialized expertise, Secoda AI delegates to purpose-built agents that collaborate and share context - search agents for data discovery, memory agents for learning from past interactions, and suggestion agents for proactive governance recommendations.
- Artifact generation: Instead of ephemeral answers, Secoda AI can generate persistent documentation, query results, and visualizations that live beyond the chat.
- Integration-aware execution: It runs SQL directly against your connected data sources with proper permissions and formatting, not just generating code snippets.
- Automated documentation: Secoda AI creates and updates documentation based on schema changes, usage signals, and tagging patterns.
- Persona-aware responses: Answers adapt depending on whether you’re an analyst, engineer, or business user. Always governed by your workspace permissions.
- Deep metadata access: Unlike standalone LLMs, Secoda AI has direct access to your schemas, lineage graphs, and glossary terms.
- Purpose-built RAG: Our retrieval system expands query context with upstream/downstream dependencies using lineage-aware logic.
- Governance-aware reasoning: PII masking and classification rules are enforced automatically to keep responses compliant with your policies.

2. How is Secoda AI optimized for data teams and governance workflows specifically?
Secoda AI is embedded across the product experience to streamline governance and discovery workflows:
- Conversational discovery: Ask natural language questions and get responses grounded in your catalog, lineage, and query logs.
- SQL assistant: Write, debug, and optimize SQL with contextual awareness of your warehouse structure and access controls.
- Lineage-aware analysis: Automatically identify upstream/downstream impact when exploring a table, column, or query.
- Governance automation: Secoda AI recommends ownership assignments, classification tags, and policy actions based on how data is being used.
- Semantic search: Go beyond keywords. Secoda AI understands relationships between metrics, tables, and business concepts.
- Auto-generated documentation: Table and column descriptions are written and maintained by AI using real metadata and usage patterns.

3. What parts of the product leverage AI most deeply today?
The most AI-integrated areas of Secoda include:
- The AI Assistant: Enables real-time, conversational queries across your data stack with intelligent tool selection and model routing.
- Search & discovery: AI-enhanced search uses semantic understanding and metadata relationships to deliver better results.
- SQL & query support: Assists in writing, transforming, and explaining SQL based on the actual structure of your warehouse.
- Lineage & impact analysis: Automatically surfaces dependencies and impacts across pipelines and reports.
- Documentation workflows: Auto-generates and updates documentation based on schema evolution and historical changes.
4. What’s next for Secoda AI?
We’re continuing to push the boundaries of what a data-native copilot can do. Coming soon:
- Enhanced multi-agent architecture: Building on our current specialized agents for search, memory, and suggestions, we're expanding our multi-agent system where purpose-built agents collaborate seamlessly on complex workflows. Each agent maintains its own expertise - whether it's comprehensive data discovery, learning from interaction patterns, or generating targeted governance proposals - while sharing context through structured delegation and intelligent result synthesis
- Proactive suggestions: Secoda AI will begin surfacing recommended glossary terms, descriptions, monitors, and automations based on what it sees in your workspace.
- AI automation blocks: Add AI-driven steps to Automations, enabling prompt-based metadata updates across filtered resources, with support for human review, testing, and custom logic.
Get started with Secoda AI
Secoda AI is built as an orchestration of reasoning, retrieval, memory, and governance, designed specifically for data teams. Its architecture includes hybrid model routing, permission-aware retrieval augmented generation (RAG), and tool-driven execution. These choices are grounded in a core belief: data work should be approached with the same intelligence and structure as software engineering.
As we continue to evolve the platform, we’re focused on making Secoda AI even more proactive. That means catching broken lineage before it becomes an issue, suggesting documentation when something changes, and using memory to help teams scale best practices without repeating the same work twice.
We’re always listening to feedback, experimenting with new workflows, and working closely with our customers to define what responsible, high-impact AI in data governance looks like. If you’re using Secoda AI and have ideas, we want to hear them.
.png)
.png)








