



Meet the only AI assistant built for data. Analyze, document, and answer any data question — fast.
 Learn more
Learn moreSecoda uses advanced AI to help teams answer data questions, manage governance, and streamline analysis, documentation, and discovery. Behind the scenes, Secoda runs on a coordinated multi-agent AI architecture designed to reflect how strong technical data teams operate. Each agent has a specialized role, yet they work together through a central orchestrator to manage complex workflows.
In this blog, we’ll walk through how Secoda AI’s multi-agent system works and how each agent contributes to improving speed, clarity, and efficiency across your data environment.
Inside Secoda’s multi-agent AI framework
Secoda’s architecture includes one central orchestrator agent, along with several specialized subagents. Each agent is designed to take on a specific technical task. By dividing responsibilities in this way, Secoda can respond to user queries with both speed and accuracy, even when the request spans multiple workflows or tools.
The current agent framework includes:
- Central orchestrator agent
- Search agent
- Git agent
- Memory agent
- Suggestion agents
- Observability agent
- Cataloging agent
- Governance agent
- Documentation agent
- Execution agents
- Query agent
- Visualization agent
- Analysis agent
- Automation agent
Each of these agents plays a focused role. The central orchestrator coordinates their work and synthesizes responses so users get a complete, reliable answer in one place.
1. Central orchestrator agent
The central orchestrator agent is the backbone of the system. It handles the full lifecycle of a user request, from understanding the question to delivering a clear, complete answer. This agent breaks complex questions into smaller tasks, assigns those tasks to the right subagents, tracks their progress, and assembles the results into a single, easy-to-follow response.
What it does:
- Parses natural language queries and identifies user intent
- Breaks requests into structured, technical subtasks
- Delegates tasks to specialized agents and manages their execution
- Tracks task progress and coordinates responses
- Synthesizes all outputs into a single, complete answer
How it works:
- Maintains memory across multi-step conversations to preserve context
- Executes tasks in parallel across agents to reduce latency and improve responsiveness
- Merges agent outputs into a unified response, resolving overlaps and filling in gaps
- Connects directly to SQL engines, metadata systems, visualization tools, and governance frameworks to take real action
This agent ensures that every user request gets answered with clarity, speed, and precision.
2. Search agent
The search agent is responsible for finding the most relevant metadata, documentation, and lineage based on the user’s question. It’s optimized for semantic understanding, so it can retrieve the right results even when the phrasing or terminology varies.
What it does:
- Runs hybrid searches across metadata, documentation, lineage, and business definitions
- Prioritizes results based on context and user intent
- Retrieves matching assets using both exact keyword matches and semantic similarity
How it works:
- Integrates Elasticsearch metadata search with an external embedding service
- Supports both keyword-based exact matches and semantic similarity retrieval
- Combines scores from both systems to rank results for higher precision and recall
This agent ensures that users don’t waste time digging through folders or guessing names. It surfaces answers that match the intent behind the question, not just the exact keywords.
Git agent
In addition to metadata and docs, Secoda also includes a dedicated Git agent for searching product code and dbt projects. Unlike the general Search agent, it clones repos locally and runs filesystem searches (without indexing) to preserve privacy. Instead of browsing folders or running manual searches, users can simply ask questions and get contextual answers.
What it does:
- Searches through product code, dbt projects, and other Git-tracked resources
- Surfaces logic, definitions, and file references that answer product and technical questions
How it works:
- Clones the repository locally and performs targeted searches on the filesystem (no persistent indexing, preserving privacy)
- Runs keyword and pattern matching to locate relevant code or project files
- Sends the most relevant snippets to the LLM to generate clear, contextual explanations
- Supports both direct lookups (“Where is the dbt test for X defined?”) and exploratory queries (“How does access control work in the product?”)
This agent makes institutional knowledge stored in Git repos accessible through conversation, without indexing or exposing source code.
3. Memory agent
The memory agent helps Secoda AI learn over time. It remembers what’s important, from individual preferences to workspace-wide best practices, so teams don’t have to start from scratch every session. This leads to faster, more contextual responses that feel naturally aligned with how you work.
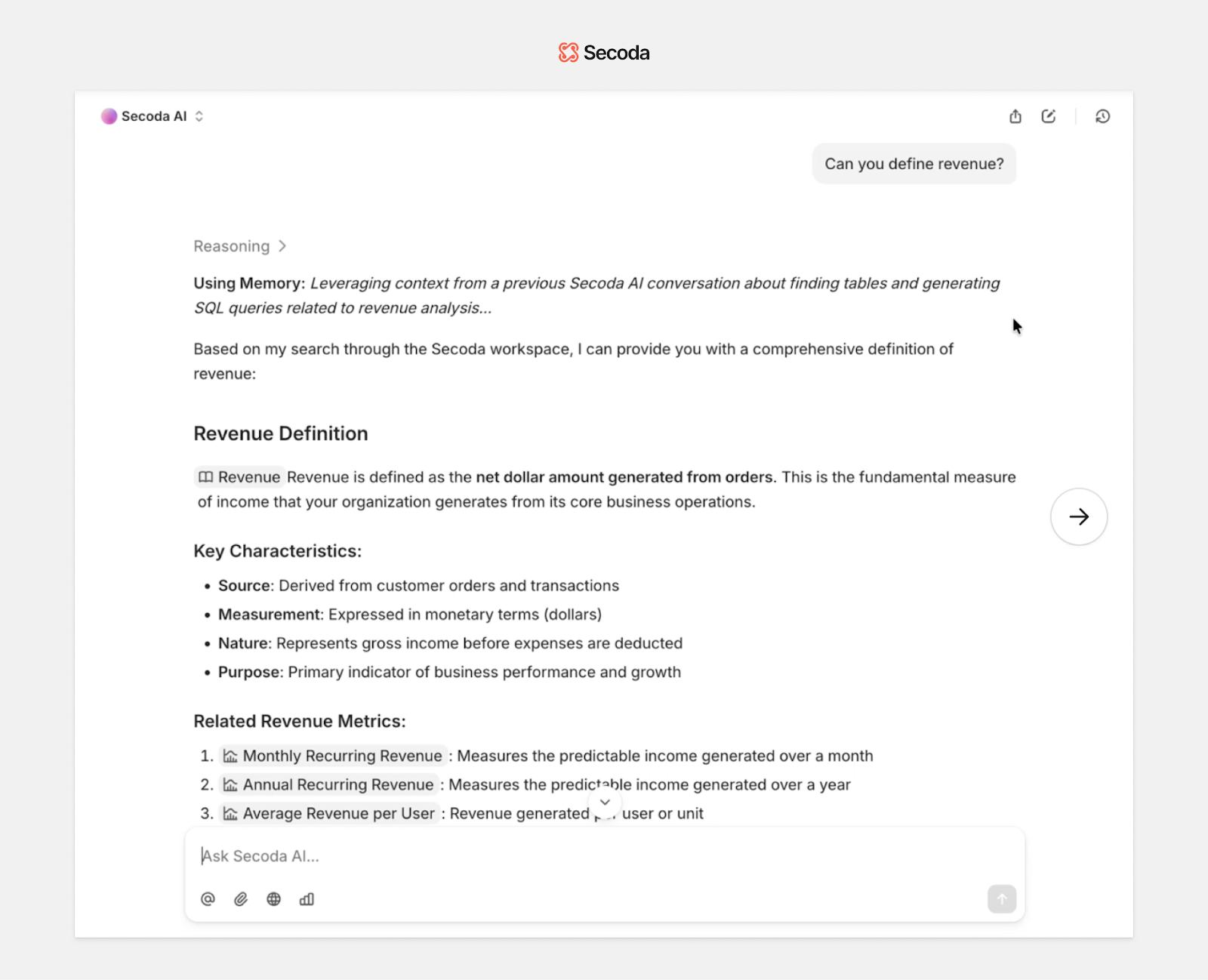
What it does:
- Learns from past conversations to improve assistant performance
- Captures personal preferences and saves frequently referenced facts
- Stores successful strategies, tool sequences, and fixes across the workspace
How it works:
- Uses a hybrid memory system:
- Personal Memory is private and at the user level
- Workspace Memory is automatically updated and shared across the org
- Analyzes interaction patterns and surfaces recurring insights
- Includes research tools like add_memory, take_note, and get_recent_prompts to track and reuse helpful context
- Allows users to guide memory with thumbs up/down feedback directly in chat
This agent makes Secoda AI more than just a chatbot. It becomes an intelligent partner that gets better with every interaction, learning what matters to you and your team, and making each answer feel one step ahead.
4. Suggestion agents
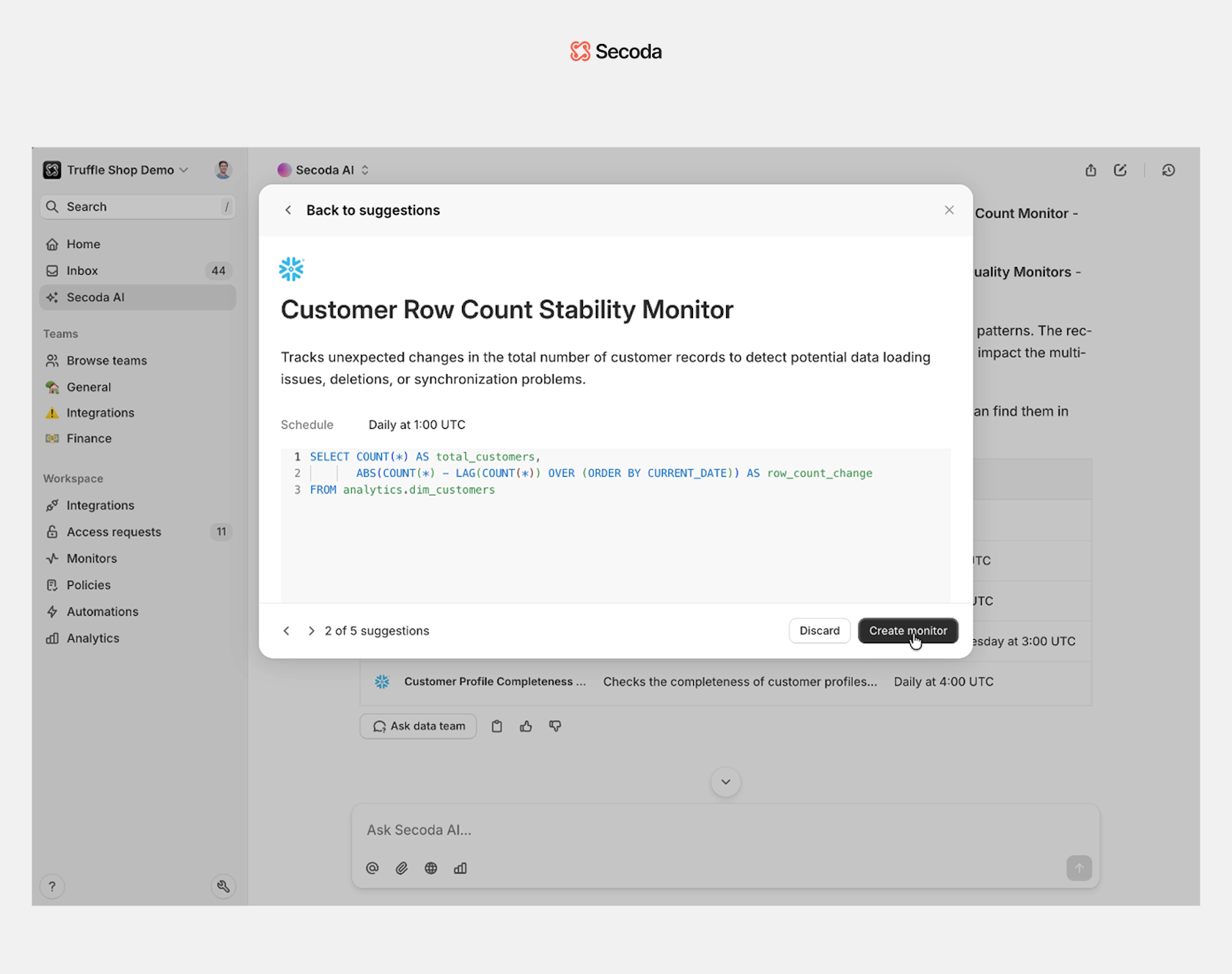
Observability agent
The observability agent helps teams stay ahead of data quality issues. It analyzes how data is used across the organization and automatically recommends where to set up monitors, what thresholds to apply, and how to schedule alerts.
What it does:
- Identifies high-impact tables and columns based on usage patterns
- Proposes detailed monitoring strategies, including SQL logic, alert thresholds, and scheduling
- Uses statistical profiling to reduce false positives and focus attention on real anomalies
How it works:
- Analyzes historical patterns to detect volatility and flag risk-prone areas
- Generates SQL queries automatically, tailored to the asset's characteristics
- Integrates with alerting and scheduling systems to make monitors actionable from day one
This agent reduces the manual effort of setting up monitors and helps teams focus on the data that matters most. It makes it easier to scale quality checks without adding more manual work.
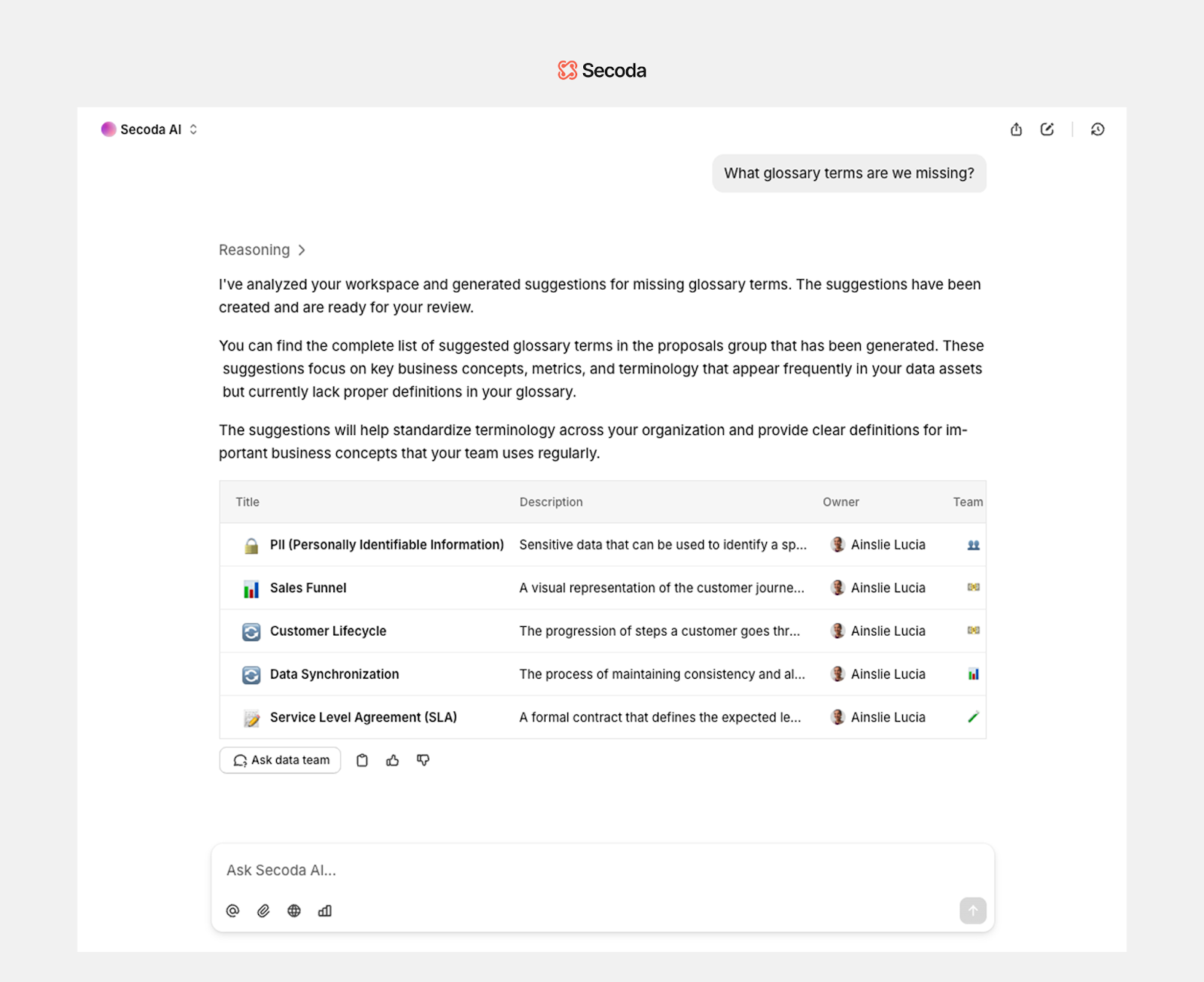
Cataloging agent
The cataloging agent strengthens documentation by identifying terms that are frequently used but lack clear definitions. It helps build a consistent vocabulary across teams by proposing business definitions linked to actual data usage.
What it does:
- Detects commonly used terms that are missing or poorly documented
- Generates structured, easy-to-understand business definitions
- Links glossary entries back to data assets to improve navigation and discoverability
How it works:
- Uses NLP models to extract and summarize terminology from queries, metadata, and usage trends
- Analyzes historical usage to prioritize high-value terms
- Pulls context from metadata APIs to inform and support each definition
This agent helps reduce ambiguity across teams and ensures documentation evolves alongside how data is actually used.
Governance agent
The governance agent is focused on data governance. It recommends governance tasks by analyzing policies, compliance gaps, and coverage across your data assets. This helps teams stay aligned with internal standards and external regulations without needing to track every detail manually.
What it does:
- Surfaces recommended governance actions based on policy gaps or missing coverage
- Identifies non-compliant resources and highlights areas that need attention
- Helps enforce frameworks by mapping policies to real-time metadata and usage
How it works:
- Uses tools to retrieve relevant standards and rules
- Applies policy compliance checks to flag issues across datasets, tools, and domains
- Evaluates policy coverage to detect entities missing appropriate governance controls
- Routes findings through the Suggestions Agent to generate actionable recommendations
This agent turns governance into a continuous process, one that’s embedded into daily workflows and not buried in static documentation. It gives data teams the visibility they need to drive accountability and stay audit-ready, without the overhead.
Documentation agent
The documentation agent automates the creation and improvement of data documentation. It turns technical metadata into clear, human-readable descriptions that help users understand what each table, column, or process actually means.
What it does:
- Auto-generates resource descriptions using metadata and usage context
- Fills in missing documentation or improves existing entries
- Suggests tags, owners, and related assets to increase discoverability
How it works:
- Parses schema details and lineage to infer the purpose of data assets
- Uses large language models to write readable, consistent documentation
- References past documentation patterns and workspace best practices to stay aligned
This agent saves teams hours of manual work and helps ensure documentation doesn’t fall out of date. It keeps the catalog useful, accurate, and accessible, especially for new team members.
5. Execution agents
Query agent
The query agent converts natural language requests into efficient SQL and runs them directly in your connected databases. It’s designed to help both technical and non-technical users get answers faster, without needing to write or tune SQL themselves.
What it does:
- Translates analytical questions into accurate, high-performance SQL
- Executes queries directly in Snowflake, BigQuery, Databricks, Redshift, and other SQL-compliant warehouses
- Optimizes queries using schema insights, indexing strategies, and warehouse-specific logic
How it works:
- Leverages machine learning models trained for natural language to SQL conversion
- Uses query parsers and optimizers to improve performance and accuracy
- Connects through native database integrations to run live queries and return results in real time
This agent bridges the gap between natural language and technical execution, helping teams move from question to insight with fewer handoffs.
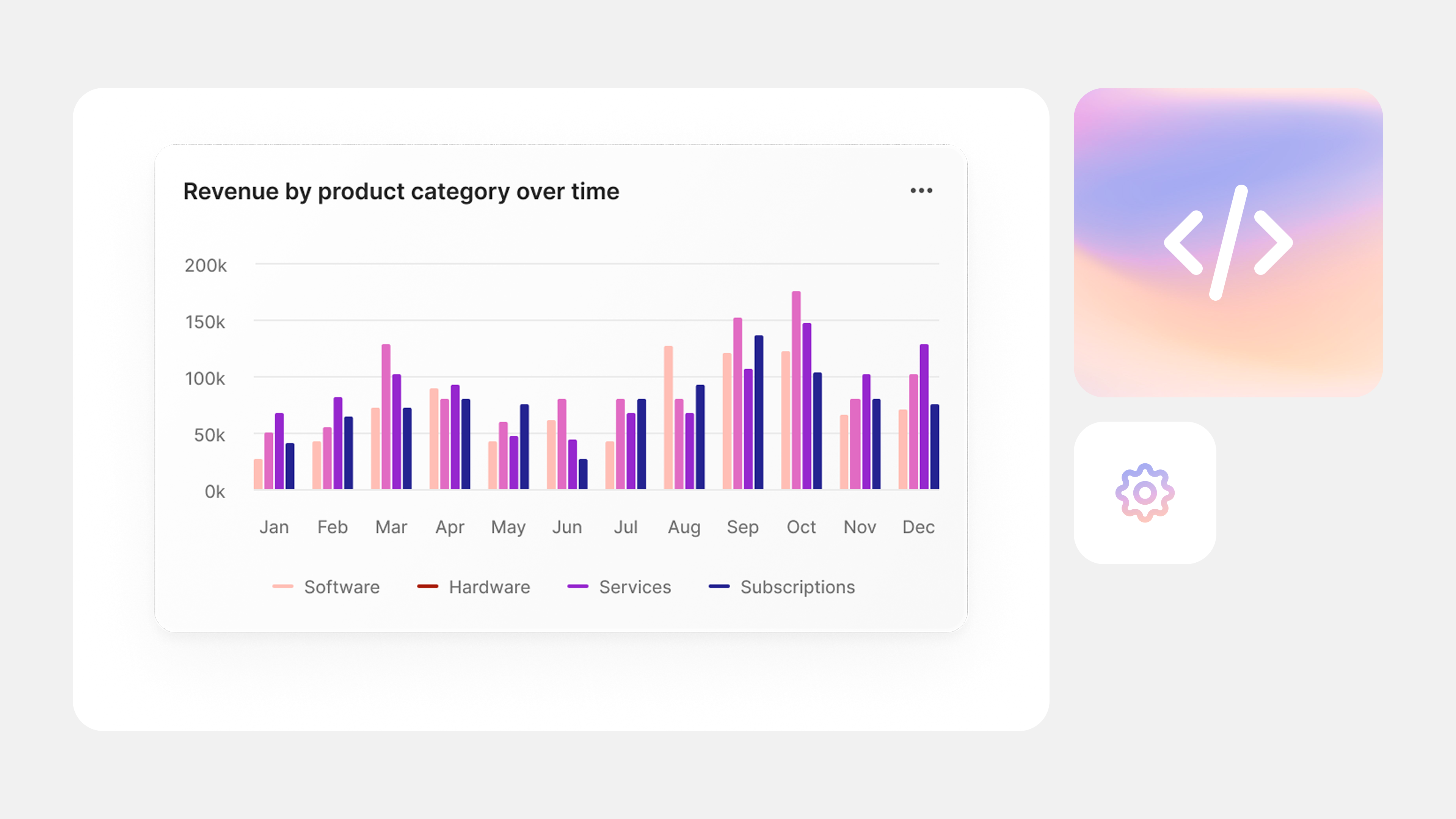
Visualization agent
The visualization agent transforms raw query results into visual insights. It selects the right visual format based on the data and the user’s intent, then builds interactive dashboards that help teams explore trends and spot outliers quickly.
What it does:
- Dynamically selects visualization templates based on intent and data structure
- Generates dashboards that reflect live SQL results and update as the data changes
- Renders interactive visuals that support deeper exploration and user engagement
How it works:
- Uses advanced frameworks to generate charts and graphs
- Embeds dashboards directly into the platform using rendering libraries
- Integrates with interactive widget libraries to support filtering, hovering, and drill-down analysis
This agent makes it easy to move from raw output to visual storytelling, helping users communicate insights more effectively.
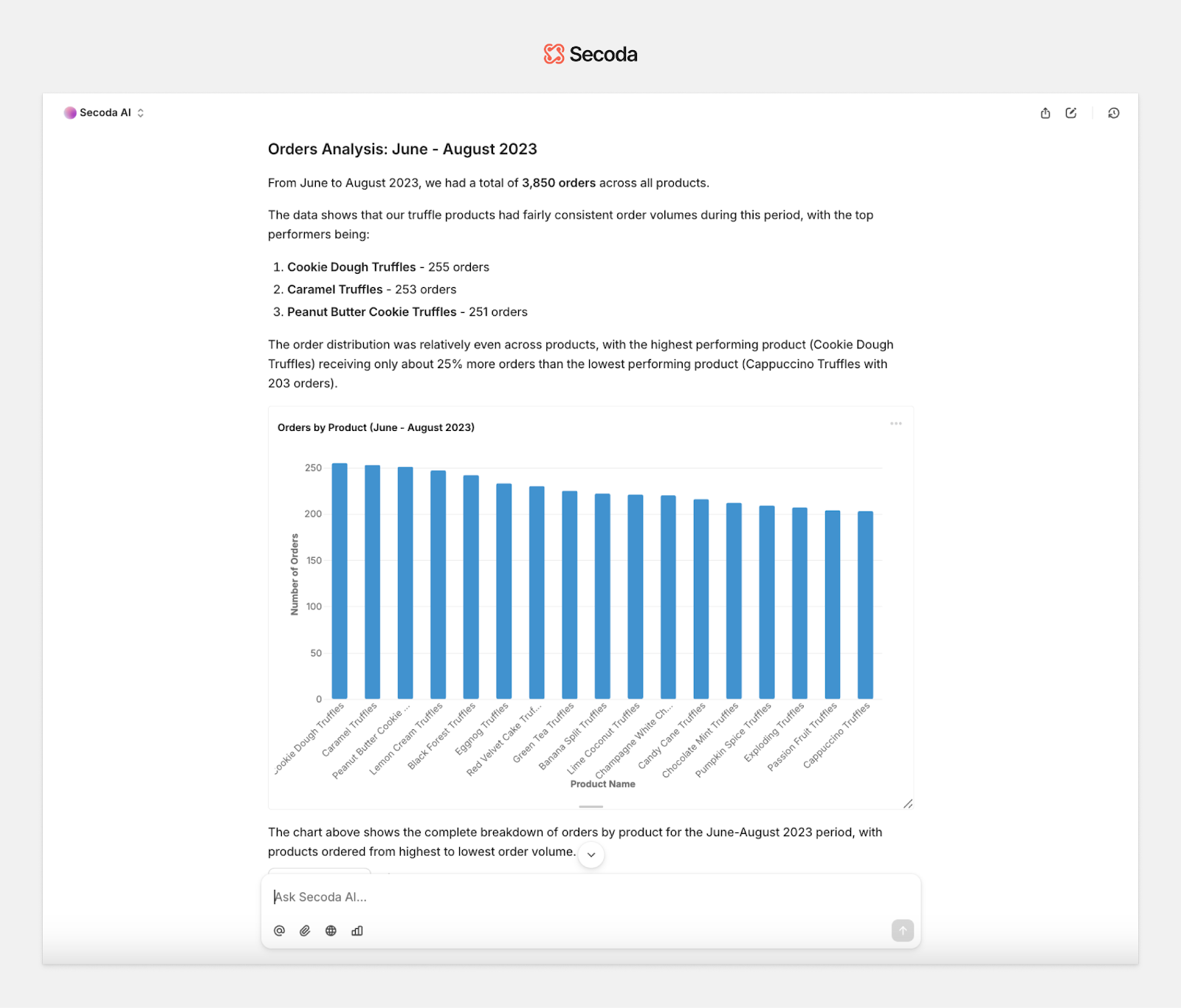
Analysis agent
The analysis agent interprets the results of queries and makes sense of them. Instead of leaving users with raw output, it explains trends, highlights anomalies, and answers follow-up questions. It acts as the interpretation layer between data and decision.
What it does:
- Summarizes SQL results in natural language
- Highlights key metrics, patterns, and unexpected findings
- Provides context-aware follow-up analysis and suggestions
How it works:
- Analyzes statistical properties of query output (e.g. distributions, changes over time)
- Uses LLMs to generate plain-language summaries tailored to the original question
- Detects relationships, comparisons, and anomalies worth flagging
This agent turns raw numbers into takeaways, making analysis faster, more accessible, and easier to act on for all users.
Automation agent
The automation agent reduces manual overhead by automatically enriching data assets with critical metadata. Instead of relying on data teams to tag, assign owners, or write descriptions by hand, the automation agent uses AI to generate and apply these updates at scale.
What it does:
- Suggests and applies tags based on schema, usage, and context
- Assigns likely owners to resources using access and query history
- Generates or improves descriptions directly from metadata and raw data
- Keeps catalog metadata current without requiring constant human input
How it works:
- Analyzes schema structures, lineage, and usage logs to infer context
- Applies AI models to generate plain-language descriptions for tables and columns
- Maps frequent access patterns back to users or teams to recommend ownership
- Surfaces suggested tags aligned with business definitions and applies them consistently across assets
- Integrates with Secoda automations to continuously update metadata as new resources appear
This agent ensures that your catalog doesn’t go stale. By handling repetitive metadata management automatically, it keeps documentation complete and searchable, while freeing up data teams to focus on higher-impact work.
Example: How the agents work together
Let’s say a user asks:
“Analyze customer data usage patterns, identify compliance and governance gaps, recommend documentation improvements and monitoring strategies, and visualize the insights clearly.”
This is a multi-step request. Here’s how Secoda’s agents handle it from start to finish:
Step 1 – Breakdown and task assignment
The Secoda central orchestrator agent parses the request and breaks it into individual tasks. Each one is assigned to the right agent based on its specialization.
Step 2 – Parallelized subagent execution
Step 3 – Response synthesis
Secoda AI gathers results from all other agents. It removes redundancy, resolves conflicts, and assembles a unified response that includes raw data, explanations, documentation suggestions, and visual dashboards.
Step 4 – Final output
The user receives a complete answer: analytics, compliance observations, glossary updates, recommended monitors, and a visual summary, all in one place.
Technical benefits of the multi-agent system
Secoda’s architecture is built for scale, speed, and precision. Each agent is focused on a specific task, and the central orchestrator agent ensures everything runs smoothly across the system.
Key benefits:
- Tasks run in parallel, reducing wait times for complex or multi-step workflows
- Specialized agents use targeted tooling to improve accuracy and reduce manual overhead
- The system adjusts automatically based on the complexity of each request, optimizing how agents are used
- Stateful memory keeps track of multi-turn conversations, so follow-ups stay connected and context is preserved
- Every step is logged, giving teams full visibility into how answers are generated and where improvements can be made
This architecture supports fast, reliable automation across a wide range of technical workflows, without adding complexity for the user.
Final thoughts
Data work has traditionally been slowed down by repetitive tasks, fragmented tools, and the need for technical expertise at every step. That makes it hard for both data teams and business users to move quickly.
Secoda’s multi-agent AI architecture changes that dynamic. By combining a central orchestrator with specialized agents, the platform automates discovery, monitoring, governance, and analysis in one coordinated system. Each request is broken into the right tasks, assigned to the right agent, and delivered back as a complete, reliable answer.
The result is a practical way for teams to get more from their data with less manual effort. Every workflow runs with speed and precision, so organizations can spend less time maintaining their stack and more time using data to drive decisions.
To learn more, visit the Secoda documentation and our technical guide to Secoda AI.
.png)
.png)








